

Basic Wizard Guide to Dune SQL and Ethereum Data Analytics
Explaining how Ethereum maps to Dune's tables and giving use case examples for all the basic SQL you need to know to be a data wizard

If you already know basic SQL and how to navigate onchain data in Dune tables, then you should read the advanced guide:


Here are all the concepts you’ll need to know to do all the basic analysis in Dune - your first step to becoming a wizard! Take your time with it, you don’t have to try and learn everything at once.
I’ll have a more advanced guide with optimization techniques out soon too. The main optimization tip you need to know is always filter on time and join on the unique id or hash columns (if they exist in your table).
If you have any questions (confusion about any functions, or think I’m missing an important function), let me know by dming me on Twitter.
Want to join an onchain data community? I’ve created an NFT passport and quest system that any analyst can participate in.
🔍 Learn about the Bytexplorers, then mint your passport and join in
🗺 Learn using a full roadmap to becoming an expert data analyst
How the EVM translates to Data Tables in Dune
You can read about the basics of relational databases here. If you don’t know what “tables” mean, think of every transaction as a row in an excel sheet. Tables in Dune all have shared/related columns, most commonly being a contract/wallet address or transaction hash. EVM refers to “Ethereum Virtual Machine”, which chains like Ethereum, Gnosis, Avalanche, Arbitrum, Optimism, Polygon, and Binance all use as a standard - so the raw data outputs are all roughly the same.
Dune has a lot of tables. If you’ve checked out the explorer in the query interface, then I’m sure you’ve already been overwhelmed. I’ve shown a hierarchy of tables below so you can understand the icons you see and the types of tables they correspond to:
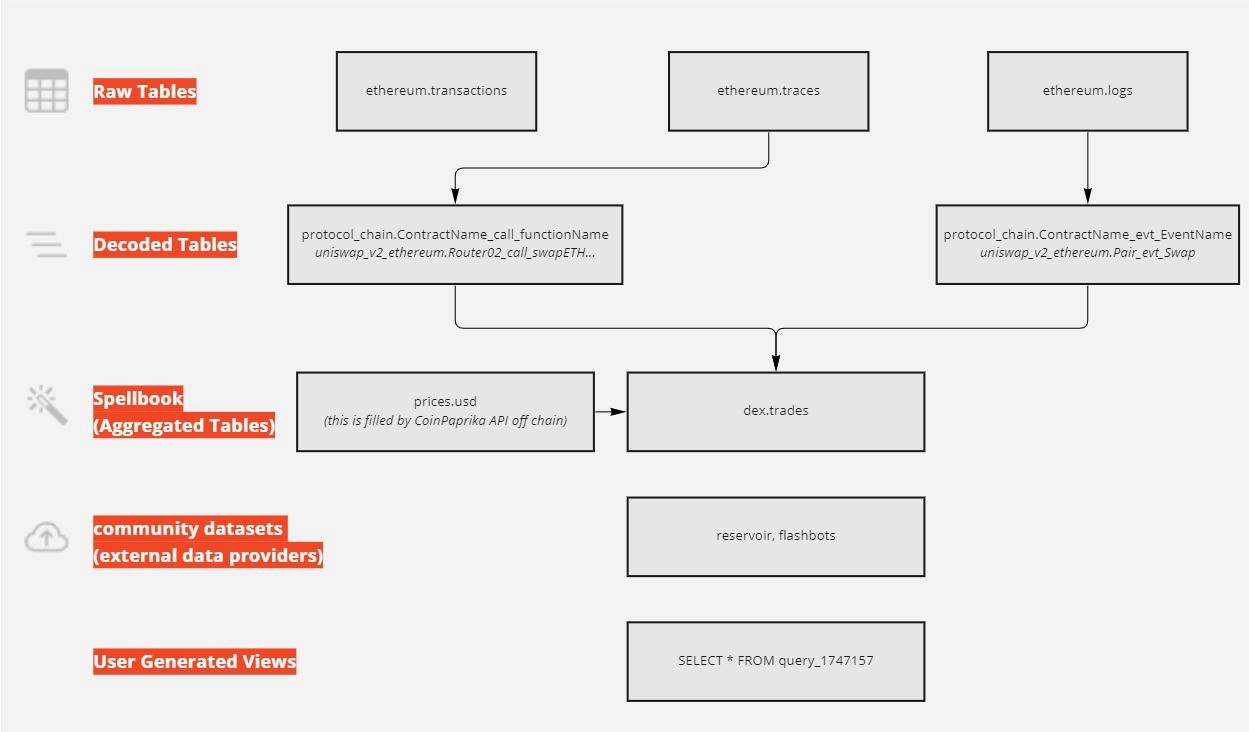
The simplest table is the “transactions” table, where from is the wallet signing the transaction, to is the address that was interacted with, and input is the data passed to call a function. The relationships require more EVM knowledge to navigate as you get into more complex tables like traces/logs or decoded tables. Transaction hash (hash or tx_hash) is unique in just the transactions table, in every other table there can be duplicates based on how the transaction was executed.
I’ll keep saying it - all of these tables relate to one another in some way. All logs and traces can be tied to a transaction, and all transactions can be tied to a block. You need to focus on understanding the order in which the data was created in (on-chain), and how that then informs how the tables below are populated.
💡 Each chain has its own set of independent raw and decoded tables; some chains will share spellbook tables. You can cross-query any table, regardless of the chain the data came from.
Wallet addresses (EOAs) can be joined across chains, but joining Ethereum to Optimism data on transaction hash or blocknumber is nonsensical.
Raw Tables: These are the
transactions,traces,logs, andblockstables representing blockchain data in the rawest form: mostly byte arrays. You can find column descriptors for these in the Dune docs. To understand how the data flows between them:You submit a transaction (call a contract, send someone ETH). Each transaction occurs in specific blocks. Transactions have an index denoting the order in which transactions executed in the block (column is called tx_index outside of the transaction table).
That transaction will set off traces (contract calls other contracts, deploys a contract, sends ETH to somewhere, etc). Traces all have a trace_address (see traceAddress here). You can order traces for each transaction by taking the cardinality of the trace_address column.
Those function calls can emit events as they execute (stored in logs). Logs are ordered across the block based on index (column is called evt_index outside of the logs table). Events cannot be emitted outside of a transaction!
💡
creation_tracesis a subset of traces that only tracks contract deployments.Decoded Tables: Based on contract ABIs submitted to a contracts table (i.e.
ethereum.contracts), functions and events are converted to bytes signatures (ethereum.signatures) which are then matched againsttracesandlogsto give you decoded tables such asuniswap_v2_ethereum.Pair_evt_Swapwhich stores all swaps for all pair contracts created by the pair factory (you can filter for a specific one by looking at thecontract_addresstable for events.Each function and event get its own table. Read functions will show up but can’t be queried (i.e. table will be empty for something like
balanceOf)All decoded tables carry down the main transaction metadata columns such as tx_hash, block_time, and block_number with a
callorevtprefix.
Spellbook Tables: These are tables created using SQL based on Raw, Decoded, or Seed file tables. They run on a scheduler, so they have a data delay compared to raw/decoded tables.
stuff like ERC20 or NFT token names and decimals are “seed files” where you’re essentially uploading a CSV dataset to Dune.
tokens.erc20andtokens.nftare both very useful tables for almost any query.Very common events like token transfers also have their own spellbook table, such as
erc20_ethereum.evt_Transferwhich holds all transfer events for all ERC20 tokens, whether we have them in our tokens tables or not. erc721 and erc1155 have the same tables.prices.usdsemi falls into this category, and gives you ERC20 token prices for almost every token.dex.pricesis a similar table that calculates prices based on DEX rates, instead of some off-chain API.
💡 For any token-based table, you should always join by address instead of symbol due to uniqueness constraints.
Community Datasets: These are datasets we ingest from other providers. Flashbots MEV datasets and Reservoir NFT trading datasets both fall under this category.
These datasets will still nicely join to Dune datasets by transaction hashes and addresses.
User-Generated Views: DuneSQL turns every public query into a “view”. You can query any of them with the
query_<id>syntax, and it will pull in the referenced query text as a CTE.This currently doesn’t work with parameters in queries.
⚠️ The query has to have been created using the DuneSQL engine to be referenced in another query.
Let’s say a token swap in Uniswap occurred in a single transaction:
There would be a single transaction added to the
ethereum.transactionstable.The swap would get its own row in the
ethereum.logsbecause of the Swap() event, and the corresponding decodeduniswap_v2_ethereum.Pair_evt_Swapwould be filled too.Because there has to be one token transferred in and one token transferred out, we’d also find two transfer event added to the
ethereum.logstable as well anerc20_ethereum.evt_Transferspellbook table.
Each swap would get its own row in the
ethereum.traces. The decoded function tableuniswap_v2_ethereum.Pair_call_swapwould be filled too.The token transfers would add two more rows to the
ethereum.tracestable because some sort of transfer function must have been called on the token contracts. There is no transfer function spellbook table, so nothing is added there.
Each swap would lastly be added to the spellbook
dex.tradestable.If it were a MEV swap, then we’d find it in the community dataset
flashbots.mev_summarytable as well.
As you can see, these tables contain different slices of the same transaction, which can be leveraged in different ways! If that last sequence was confusing, try out any of the sections of this linked query to explore how to swap function/event shows up across raw, decoded, and spellbook tables.
If you want to learn how to work with raw bytes data from transactions, you can learn to do this here.
📚 Learn to read transactions, logs, and traces on any block explorer. Being able to read a block explorer is the most important and fundamental skill, otherwise you’re only learning to query a few tables that are spoon fed to you.
You’ll also want to learn how to read and navigate solidity contract code.
Basic SQL Concepts:
There are dozens of examples for the most commonly queried concepts in this dashboard.
Generally, you should have the below organization in mind by the end (where brackets [ ] indicate an optional statement, i.e., the query will run even if you don’t have those). The order of the brackets is very important, for example, you can’t put a WHERE statement before a JOIN statement or after a GROUP BY statement - otherwise your query will error out.
[ WITH subquery as (...) ]
SELECT [ ALL | DISTINCT ] some_columns
[ FROM some_table ]
[ [LEFT...] JOIN some_table ON conditional_logic ]
[ WHERE conditional_logic ]
[ GROUP BY [, ...some_columns] ]
[ HAVING conditional_logic ]
[ { UNION | INTERSECT | EXCEPT } [ ALL | DISTINCT ] select other_query]
[ ORDER BY some_column [ ASC | DESC ] [, ...] ]
[ OFFSET some_number_rows ]
[ LIMIT some_number_rows ]
⚠️ the above is simplified for readability, full technical version is here. There are also some functions that I have omitted from this guide that are supported in Dune SQL; you can find the base Trino SQL ones here.You can click the query link and play with any queries right in Dune by “forking” them.
SELECT, FROM All Basics
* = this means “all” columns
columns = these are the columns you can see
constants = you can select a constant, which will be added as a column for all rows.
aliasing = any column and table can be renamed to something else (saves you some typing)
LIMIT = returns the first X amount of rows
So let’s put these concepts together in one query:

DISTINCT = returns unique rows for whatever combination of columns you’ve selected.
This is usually used to help you find unique addresses or transaction hashes. Below we use it to get all the unique suppliers into the “Aave v3” lending “Pool” contract on the Optimism chain by tracking the “Supply” event emitted by deposits. They’re supplying the pool so that someone else can borrow the token, and pay an APR. Hopefully, you’re seeing the pattern here
namespace_chain.ContractName_evt_EventNamethat is consistent across all decoded tables.

CTE = allows you to store a subquery as a variable, and reference it like a table later on in the query. These can be nested.

Types and cast()
Below are some of the main types you’ll need to know:
varchar = also known as a string. Most columns default to this.
double = you should cast basically any numerical value into this
hex/bytea = this is the base type for most raw data like “data” in the
transactionstable or any of the topics in thelogstable. Anything that starts with “0x…” is a bytea type.bytea2numeric()is your best friend for converting bytea columns into numerical form. You have to substring() the results into 32-byte (64 characters) increments though.
timestamp = many date functions don’t behave well if the types of the columns are not consistent. Casting to timestamp is the easiest way to fix this.
The cast() function will allow you to change column types (where applicable).

ORDER BY
ASC/DESC = sort all rows by some column in ascending or descending order
this is useful for ordering and then using a LIMIT so you can get “top 100” or “bottom 100”. Let’s take the last query and do an order first to get the top 100 largest values transferred.


NULLS FIRST/LAST = if there are null values, show them first or last
I mainly use this for debugging purposes. Having them first makes it faster for me to find errors.
...order by COLUMN desc nulls first
WHERE, AND, OR
There are three main operator types to know:
is [not] null (if no data exists in a row, which is common in left joins, then it is null).
[not] IN or EXISTS (these are used for checking for the existence of one row’s value in a list of values)
!=, =, >, < (these are equality operators that work on numeric and varchar types)
Here’s the most common example - filtering for only one contract address while looking at an events table:

This gives us all the swap() function calls onto the USDC/WETH Uniswap v2 pair address. Uniswap allows you to swap any two tokens in a pair, so in this case you’re either swapping USDC to WETH or WETH to USDC. Let’s say we wanted to check for WETH/WBTC pair swaps as well. Then we’d use an IN:

Now let’s say we want only swaps in the USDC/WETH or WETH/WBTC pairs in the last three days. Then we would change the query to this:

The parenthesis placement here is very important, otherwise you’d get swaps that didn’t happen in the last three days for whichever contract_address is filtered first. You can play with the WHERE queries here.
Working with time
This is a good time to cover the three basic time functions you’ll use everyday.
date_trunc(’minute’, some_column) (think of this as rounding down to the nearest interval)
now() (this literally gives you the timestamp at the time the query is being run, in UTC timezone)
interval ‘1’ day (can be minute, hour, day, month, year)
> timestamp ‘2022-02-01 00:01:00’ use this format for turning strings into timestamps.
I won’t show an example here since we’ll be using these a lot in the next sections.
common math operations
And some basic math operations, some of which we’ve already used. You get all your +, -, /, * symbols. The only others you’ll need for now are:
round(some_number, decimal_places) for rounding decimals
pow(base, power) (or 1e18 format) for mainly handling raw to actual amount conversions for tokens/values.
Like the time functions, we’ll be using these a lot in the next sections.
GROUP BY (Aggregations)
Alright, here’s where I might start to lose some of you, but just stick with it. If you’ve worked with pivot tables in excel before, then GROUP BY will not be too hard to understand. If not, think of it as running the select query for each unique id in the column(s) you are grouping by.
You can apply some aggregation function to apply to all of the selected rows for each unique id, some of which are listed below:
count
sum
avg
min
max
approx_distinct (same as
count(distinct col))approx_percentile(0.5) (gets the median or whatever quartile you want)
arbitrary (get a random value)
I’ve put them all together in a query on the last day of USDC/WETH swaps so you can see the syntax:
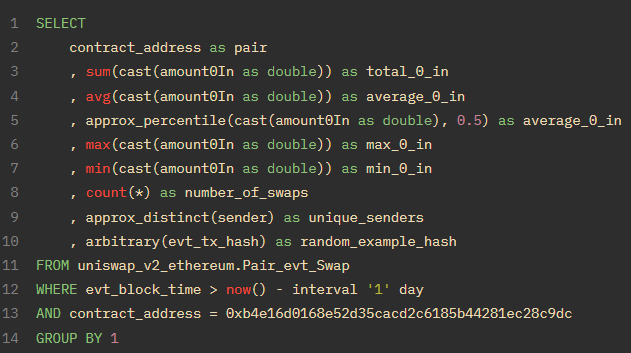

You’ll notice we’re now using the Swap() event instead of the call. Events are emitted inside of calls - so in this case the Swap() event is emitted at the end of the swap() function.
HAVING
This is like WHERE but only after GROUP BY. Let’s say you wanted the total amount swapped by a sender, but only keep those who swapped more than 100 ETH worth of tokens in the last 10 days.


At the time of me running this query (12/19/22), there were only 17 senders who swapped more than 100 ETH in the last ten days.
UNION (ALL), INTERSECT, EXCEPT
Before we get into JOINs, we’re going to go over combining selections (subqueries) row-wise. These functions require you to have consistent columns before you combine them, otherwise an error will be thrown. For a super simple example, play with this query.
For UNION ALL, the main use case for me is combining similar functions so I can have a complete set of data to start working with. For example, the swap router for Uniswap v2 (which figures out what pairs to swap through for some token X to token Y) has 8 different swap functions depending on the desired input and output token. To get all swaps, I therefore need to union all of them:

⚠️ These other three are really slow functions, so avoid them at almost all costs.
If I only put UNION then it’s the equivalent of taking the UNION ALL and then SELECT DISTINCT over all columns. INTERSECT and EXCEPT give you the duplicates or removes duplicates respectively between two selections. I usually never use these, since when I need this functionality I usually need conditional logic so I have to use some sort of JOIN instead.
JOINS
Alright - great job sticking with me so far! Play more with everything above if you’re new to SQL, it will make it much easier to digest this section if you can already start to visualize table operations in your head.
Joins allow you to combine two selections (subqueries, CTEs, tables) by column. If the join condition only produces one matching row from each table, you should only get extra columns and no extra rows.
Here’s the best graphic for figuring out what data you’re adding or removing with your join:

The most common ones you’ll need are:
JOIN (means INNER, so keep only overlapping rows)
LEFT JOIN (keep all of the original, and join any matching rows)
FULL OUTER JOIN (keep everything)
Let’s start with an easy example. Often times, event and function tables won’t contain the transactions/traces from or to columns. So, we can do a JOIN to get those addresses. In this case, LEFT JOIN and JOIN would give the same result because every event and function has a transaction hash, and every hash has a row in transactions/traces tables.

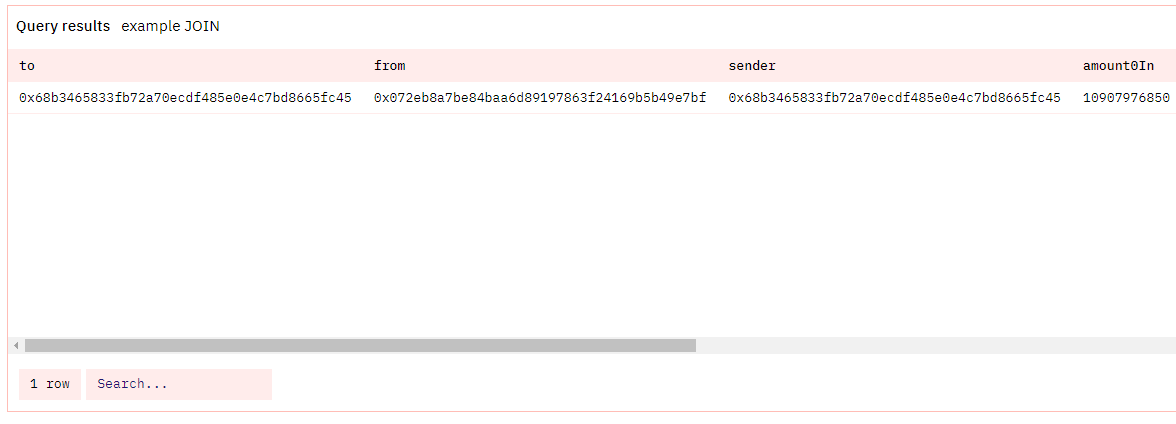
You’ll see here that sender ≠ from, and to is also ≠ to the pair address of USDC/WETH. So don’t go blindly trusting event/function columns as sources of truth, even if the name sounds similar! 🙂
For LEFT JOIN, the most common one I use is probably joining tokens.erc20 on a set of token addresses to get their symbols. I’ll cover this and what to do if you don’t get a matching symbol in the COALESCE() section next.
I typically use FULL OUTER JOIN when there’s a time series involved and I need to match them together. You can find an example of this for token balances here.
COALESCE()
This one will be unintuitive until you’ve tried it yourself. Essentially it returns the first non-null value you give it (constant or column).
SELECT coalesce(null, null, 1); --returns 1
SELECT coalesce(null, 2, null, 32); --returns 2It can be used to create a fallback column or fill null values with some placeholder constant. Let’s combine everything we’ve learned by checking which ERC20 tokens had the most notional value transferred on the last day.
All ERC20 tokens have a Transfer event, so we can put them into one table - erc20_chain.evt_Transfer. We’re taking all the Transfer events, and joining on the tokens.erc20 table to get the symbol and decimals. The tokens.erc20 table is like a community-contributed google sheet that’s been uploaded to our database.
We then group by and sum (dividing by decimals if the join exists, or just 18 as the default) across all unique erc20 tokens (given to us by contract_address and symbol).
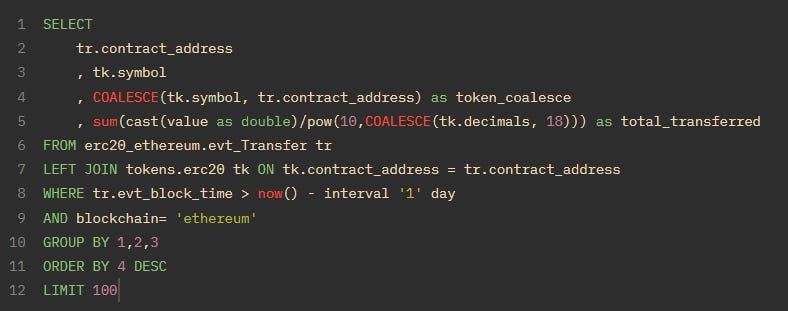

If this example makes sense to you, congrats you’re doing really well! If not, try and break it down into pieces - query the individual tables first.
try()
The try() function pairs well with math functions and casting. If the logic inside the function creates some error, it will just return null instead. If you run the following query, you’d get an error:
SELECT 1/0 --returns a query error, query will stop running
If you run it with a try(), then you’d get ‘null’ as the result
SELECT try(1/0) --returns null
If you try it with a coalesce() then you can control what the fallback value should be.
SELECT coalesce(try(1/0),10) --returns 10
CASE WHEN
Once you get into bucketing or categorizing address types or trade types, you’ll rely more heavily on CASE WHEN operations. One of the most common categorization I make is checking if an address is a contract or a wallet (EOA). You can do this by joining the creation.traces table and doing an “is null” check. All your WHERE checks work here.
Let’s check how many transactions had a to address that was a contract in the last day:


Common string operations
I’ll leave you today with some common string operations, which are only really useful in specific situations (that do still come up a lot).
lower() - useful if you’re doing string comparisons of contract names or ens names.
LIKE ‘%thing%’ - useful for partial string matching. I use it for token wrappers sometimes.

https://dune.com/queries/1781934?d=11 
concat() - this one is useful for creating hyperlinks (clickable hrefs) or more readable token/contract names.


substr() - this one is useful for working with raw bytea data. I used it in the tables examples section back at the start for selecting function signatures from transaction data.
101 Class Finished!
And there you have it! All the basic table navigation and SQL concepts you need to start working on queries 🙂 You’re ready to start learning some serious analysis with our 12 Days of Dune course next!
Once you’ve mastered the basics, go and try reading through the advanced guide:
Again, if you have any questions (confusion about any functions, or think I’m missing an important function), let me know by dming me on Twitter.

.
Appreciate you posting this; the information is very helpful.
Thanks a lot! It is so useful and comprehensive.