

[2022 Annual Guide] Web3 Data Thinking, Tools, and Teams
Frameworks for learning, building, and hiring in the Ethereum datascape.

Welcome! I’m assuming you’re a data analyst who is new to web3, starting to build your web3 analytics team, or have just taken an interest in web3 data in general. Either way, you should already be loosely familiar with how APIs, databases, transformations, and models work in web2.
For this inaugural guide, I’m going to try to keep things very concise and highlight my thoughts across these three pillars:
Thinking: why an open data pipeline re-shapes how data work gets done
Tools: an overview of tools along the web3 data stack, and how to leverage them
Teams: basic considerations and skills to have in a web3 data team
This is probably a good time to say that this is all just my view of the space, and I’ve showcased only a few facets of the tools/communities mentioned below.
Let’s get into it!
On Data Thinking
Let’s start by summarizing how data is built, queried, and accessed in web2 (i.e. accessing Twitter’s API). We have four steps for a simplified data pipeline:
events API triggered (some tweet sent out)
ingestion to the database (connection to existing user models/state changes)
transformations of data for specific product/analytics use cases (addition of replies/engagement metrics over time)
model training and deployment (for curating your Twitter feed)
The only step when the data is sometimes open-sourced is after transformations are done. Communities like Kaggle (1000’s of data science/feature engineering competitions) and Hugging Face (26,000 top-notch NLP models) use some subset of exposed data to help corporates build better models. There are some domain-specific cases like open street maps that open up data in the earlier three steps - but these still have limits around write permissions.
I do want to clarify that I’m only talking about the data here, I’m not saying web2 doesn’t have any open-source at all. Like most other engineering roles, web2 data has tons of open-source tools for building their pipelines (dbt, anything apache, TensorFlow). We still use all these tools in web3. In summary, their tooling is open but their data is closed.
Web3 open-sources the data as well - this means that it's no longer just data scientists working in the open but analytics engineers and data engineers as well! Instead of a mostly black-box data cycle, everyone gets involved in a more continuous workflow.
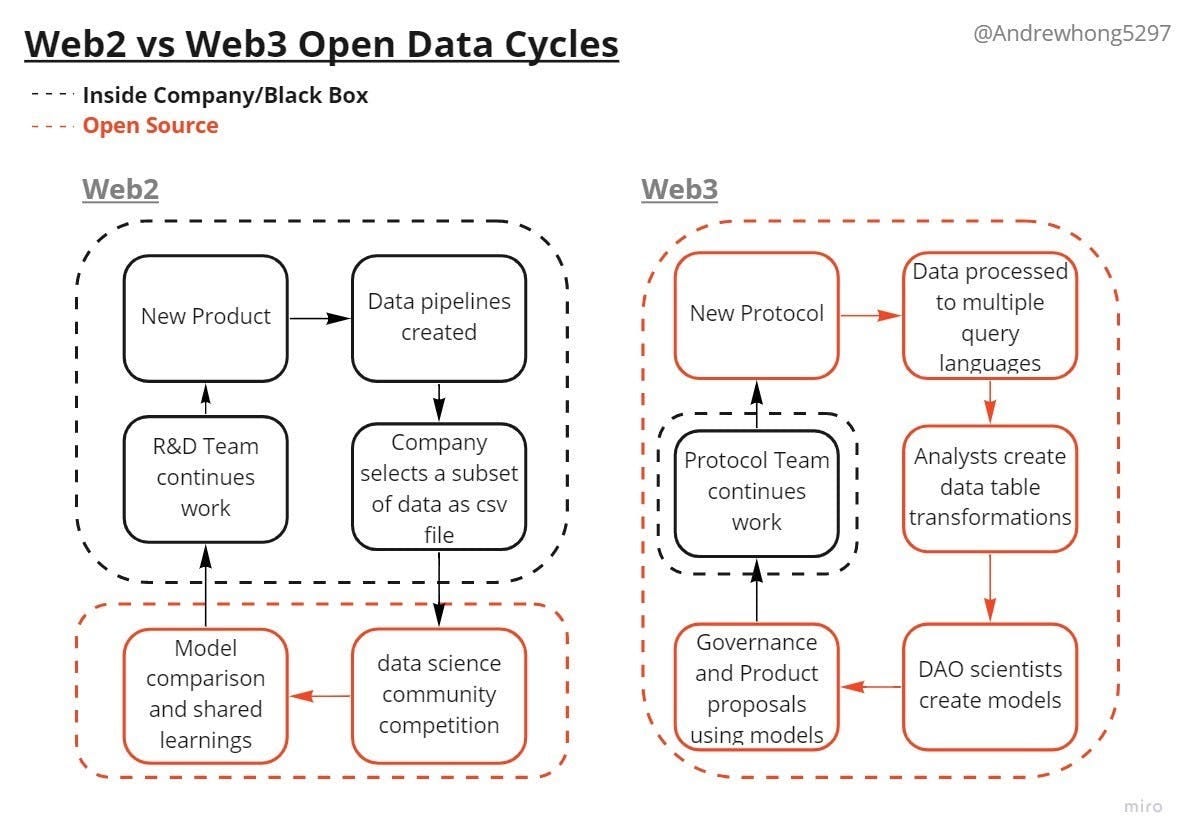
The shape of work has gone from web2 data dams to web3 data rivers, deltas, and oceans. It’s also important to note that this new cycle affects all products/protocols in the ecosystem at once.
Let’s look at an example of how web3 analysts work together. There are dozens of DEX’s out there which use different exchange mechanisms and fees for allowing you to swap token A for token B. If these were typical exchanges like Nasdaq, each exchange would report their own data in a 10k or some API, and then some other service like capIQ would do the work of putting all exchange data together and charge $$$ for you to access their API. Maybe once in a while, they’ll run an innovation competition so that they can have an extra data/chart feature to charge for in the future.
With web3 exchanges, we have this data flow instead:
dex.tradesis a table on Dune (put together by many community analytics engineers over time) where all DEX swap data is aggregated - so you can very easily search for something like a single token’s swap volume across all exchanges.A data analyst comes along and creates a dashboard using a bunch of community open-sourced queries, and now we have a public overview of the entire DEX industry.
even if all the queries look like they’re written by one person, you can bet that there was tons of discussion in a discord somewhere to piece it together accurately.
A DAO scientist takes a look at the dashboard and starts segmenting the data in their own queries, looking at specific pairs such as stablecoins. They take a look at user behaviors and business models, and start building a hypothesis.
Since the scientist can see which DEX is taking a larger share of trading volume, they’ll then come up with a new model and propose changes to governance parameters to get voted on and executed on-chain (s/o Alex Kroeger for the proposal example here).
Afterwards, we can check the public queries/dashboards at anytime to see how the proposal created a more competitive product
In the future, if another DEX comes out (or upgrades to a new version), the process will repeat. Someone will create the insert query to update this table. This will in turn reflect in all the dashboards and models (without anyone having to go back and manually fix/change anything). Any other analyst/scientist can just build upon the work Alex has already done.
Discussion, collaboration, and learning happen in a much tighter feedback loop due to the shared ecosystem. I will admit this gets very overwhelming at times, and the analysts I know basically all rotate data burnout. However, as long as one of us keeps pushing the data forward (i.e. someone creates that insert DEX query) then else everyone benefits.
It doesn’t always have to be complicated abstracted views either, sometimes its just utility functions like making it easy to search up an ENS reverse resolver or improvements in tooling like auto-generating most of the graphQL mapping with a single CLI command! All of it is reusable by everyone, and can be adapted for API consumption in some product frontend or your own personal trading models.
While the possibilities unlocked here are amazing, I do acknowledge that the wheel isn’t running that smoothly yet. The ecosystem is still really immature on the data analyst/science side compared to data engineering. I think there are a few reasons for this:
Data engineering was the core focus of web3 for years, from client RPC API improvements to basic SQL/graphQL aggregations. Work on products like theGraph and Dune really exemplifies the effort they’ve put into this.
For analysts, there’s a tough ramp-up to understand the unique cross-protocol relational tables of web3. For example, analysts can understand how to analyze just Uniswap but then struggle with adding in aggregators, other DEXs, and different token types into the mix. On top of that, the tools to do all this weren’t really there until last year.
Data scientists are used to basically going to a raw data dump and working through all of it solo (building their own pipelines). I don’t think they’re used to working so closely and openly with analysts and engineers earlier on in the pipeline. This took a while to click for me personally.
On top of learning to work together, the web3 data community is also still learning how to work across this new data stack. You don’t get to control the infrastructure or slowly build up from excel to data lake or data warehouse anymore - as soon as your product is live then your data is live everywhere. Your team is basically thrown into the deep end of data infrastructure.
On Data Tools
Here’s what most of you came here for:

*These tools are not comprehensive of the entire space - they’re just the ones that I’ve found myself or others consistently using and referencing in the Ethereum ecosystem (some of them cover other chains as well).
*The “decentralized” tag means there’s either an infrastructure network or guideline framework to stop changes from happening unilaterally. I like to think of it as decoupled infra versus cloud infra, but that will need to be its own article.
Let’s walk through when you would need to use each layer/category:
Interaction + Data Source: This is mostly used in frontends, wallets, and data ingestion to lower layers.
Clients: while the underlying implementation of Ethereum is the same (with Geth as the canonical repo), each client has different extra features. For example, Erigon is heavily optimized for data storage/sync, and Quorum supports spinning up privacy chains.
Nodes-as-a-Service: You don’t get to choose which client they run, but using these services will save you the headache of maintaining nodes and API uptime yourself. Nodes have a lot of complexity depending on how much data you want to capture (light → full → archive).
Query + Data Mapping: The data in this layer is either referenced in the contract as a URI or comes from using the contract ABI to map transaction data from bytes to table schemas. A contract ABI tells us what functions and events are contained in the contract since otherwise, all we can see is the deployed bytecode (you can’t reverse engineer/decode contract transactions without this ABI).
Transaction Data: These are the most popularly used, mostly for dashboards and reports. theGraph and Flipside APIs are used in frontends as well. Some tables are 1:1 mappings of contracts, and some allow extra transformations in the schema.
Metadata “Protocols”: These aren’t really data products, but exist for storage of DIDs or file storage. Most NFTs will use one or more of these, and I think we’ll start using these data sources more and more to enhance our queries this year.
Specialty Providers: Some of these are very robust data streaming products, Blocknative for mempool data and Parsec for on-chain trading data. Others aggregate both on-chain and off-chain data, like DAO governance or treasury data (I’m pretty confident Boardroom and DeepDAO will have more expansive APIs/query-ability in the future).
High Touch Data Providers: You can’t query/transform their data, but they’ve done all the heavy lifting for you.
“Enterprise” Services: You’ll use these a lot if you’re a VC, investigator, or reporter. You can go deep into wallets and wallet relationships using Nansen’s wallet profiler or Chainanalysis’s KYT. Or use Tolken Terminal for beautiful out-of-the-box charts on tons of projects/chains.
Enhanced APIs: These are products that bundle what would be many queries into just one, such as all token balances of an ERC20 token or pulling the contract ABI for a given address.
It wouldn’t be web3 without strong, standout communities to go alongside these tools! I’ve put some of the top communities next to each layer:
Flashbots: Working on everything MEV, providing everything from a custom RPC for protecting transactions to professional whitehat services. MEV refers mostly to the issue of frontrunning, when someone pays more gas than you (but directly to the miners) so that they can get their transaction mined first. A great story to learn about this is written here by Samczsun.
how to get involved: read through the docs to figure out which vertical interests you and jump in the discord
contact: Bert Miller
Dune Wizards: Handpicked wizards who have contributed something significant to the Dune data ecosystem.
Flipside Gunslingers: Handpicked gunslingers who have contributed something significant to the web3 data ecosystem.
how to get involved: start off in the discord and create cool custom reports.
MetricsDAO: Working across the ecosystem to tackle various data bounties on multiple chains.
DiamondDAO: Stellar data science work on governance, treasury, and token management in DAOs.
how to get involved: they literally have an organized “join” page here.
contact: Christian Lemp
IndexCoop: Lots of token and domain specific analysis to create the best indexes in crypto.
OurNetwork: Consistent data coverage of protocols and other verticals across web3 each week.
how to get involved: subscribe to the newsletter, if you do stellar analysis you’ll end up in our telegram eventually 😉
contact: Spencer Noon
(yes, we need to do better on diversity. Go follow/reach out to Danning and Kofi too, they’re amazing!)
Every one of these communities has done immense work to better the web3 ecosystem. It almost goes without saying that the products with a community around them grow at 100x the speed. This is still a heavily underrated competitive edge, one I think people don’t get unless they’ve built something within one of these communities.
On Data Teams
It should also go without saying that you want to look within these communities for the people to hire onto your teams. Let’s go further and break down the important web3 data skills and experiences, so you actually know what you’re searching for. And if you’re looking to be hired, view this as the skills and experiences to go after!
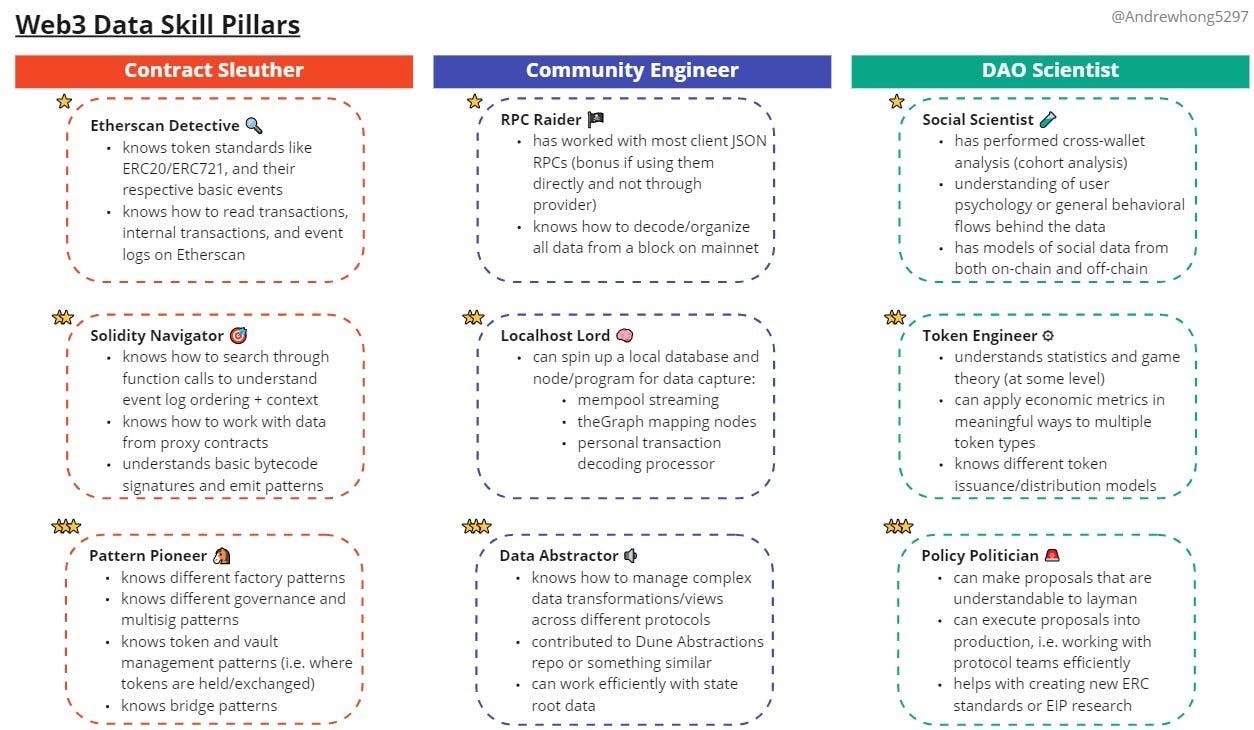
If you’re new and want to dive in, start with the free recordings of my 30-day data course which is purely focused on the first pillar. I’ll hopefully have educational content on everything here and be able to run cohorts with it one day!
At a minimum, an analyst should be an Etherscan detective and know how to read Dune dashboards. This takes maybe 1 month to ramp up to leisurely, and 2 weeks if you’re really booking it and binge studying.
There’s a little more context you should have in your mind as well, specifically on time allocations and skill transferability.
On Time: In web3, about 30-40% of a data analyst's time is going to be spent keeping up with other analysts and protocols across the ecosystem. Please make sure you aren’t suffocating them, otherwise, it’ll become a long-term detriment to everyone. Learning, contributing, and building with the larger data community are absolutely essential.
On Transferability: Skills and domain are both highly transferrable in this space. If I went to a different protocol, likely the ramp-up time would be minimal since the table schemas for on-chain data are all the same. If anything, I’ve probably already worked with that protocol’s data before even joining!
Remember, it’s less about knowing how to use the tools - every analyst should more-or-less be able to write SQL or create dashboards. It’s all about knowing how to contribute and work with the communities. If the person you’re interviewing isn’t a part of any of web3 data communities (and don’t seem to express any interest to start doing so), you may want to ask yourself if that’s a red flag.
And a final tip for hiring: pitching the analyst using your data will work much better than pitching them with a role. Graeme had originally approached me with a really fun project and set of data, and after working through it I was fairly easily convinced to join the Mirror team.
I’d also have loved to talk about team structure, but to my knowledge, most product data teams have been 0 and 2 analysts full-time. I’m sure I’ll have better-informed thoughts on this in a year or two.
I gave a talk at Dunecon about working with your analyst community:
Thanks for reading!
It’s honestly quite amazing how far data in web3 has come over the last year, and I’m very excited to see where the ecosystem grows to by 2023. I’ll try and make this a yearly thing.
If you have ideas/questions on web3 data topics you’d like to learn more about, just dm me on Twitter. I’m always looking for educational partners as well!
Special thanks to Elena as always for reviewing and making great suggestions!