

Web3 Data Guide: Sudoswap
Breaking down all the interactions and data behind Sudoswap v1

This is the first of many Web3 data guides I plan on doing. The goal here is to explain the protocol from a data analyst/engineer’s perspective. These guides aim to bring transparency to the data you see on dashboards, as well as awareness of how well (or not well) protocols are built for data analysis.
In these guides, I’ll cover protocols in three sections:
Protocol overview and high-level statistics
Main protocol interactions and how to derive the important data points from them
Some of the more complex queries and abstractions created
All data is sourced from Dune Analytics, a platform for building cross-chain queries and dashboards - most of which is open source.
I’ve also recorded a video walk through everything mentioned in this article:
A big shoutout to Jeff, Meghan, Rob, hildobby, and Danning for their help! 😊
Protocol Overview:
Sudoswap NFT AMM is a flexible liquidity pool solution for NFT (ERC721s) to token (ETH or ERC20) swaps using customizable bonding curves. This basically means you set discrete price changes per swap (i.e. 0.1 ETH price increase for each NFT sold), and you choose the side of liquidity you want to provide (NFTs to sell, or ETH for others to sell their NFTs into). Everyone’s pools are separate and only aggregated at a router level - kind of like Uniswap V3.
Over the last month, the protocol has generated a lot of momentum (some of which is wash trading, but consistently around 500 ETH a day of swaps is organic volume.
They’re sure to take off more as ERC20 pairs and ERC1155 pairs are launched, especially once aggregators integrate their markets.
I’ve created two dashboards on Dune for Sudoswap:
A general overview of swap volumes, trader activity, fees, and trending collections.
A collection-specific view that dives deeper into liquidity depth, trading prices, and pair activity on top of the basic metrics.
You can read (or listen) about why this design is better than other NFT AMMs out there, or go directly to the docs. For those wanting to gain a deeper understanding of the Solidity behind the protocol, I recommend you read the Protocol Review piece here (coming soon!).
Data Sourcing Guide
Usually, there are a few elements that factor into the difficulty of data analysis:
Complexity of contract patterns (standards like proxies, clones, diamonds)
Complexity of mid-function states (if there’s a swap, how easy is it to calculate the price)
Completeness of data across function parameters and event parameters
Number of token interactions (one token in, one in one out, wrapping, bridging)
How much math (interest rates, pricing curves, rebases, and anything that updates continuously even if no on-chain interactions occur)
Documentation and code/developer accessibility (how quickly can I find answers to questions)
I won’t go into a complete scorecard in this guide, but will probably build up to one in the future. Usually, when I start my analysis, I figure out the main user interactions and then list out all the variables I can get about each one.
Below is my breakdown of interactions for Sudoswap. My DMs are always open for feedback on what could make this more clear/informative!
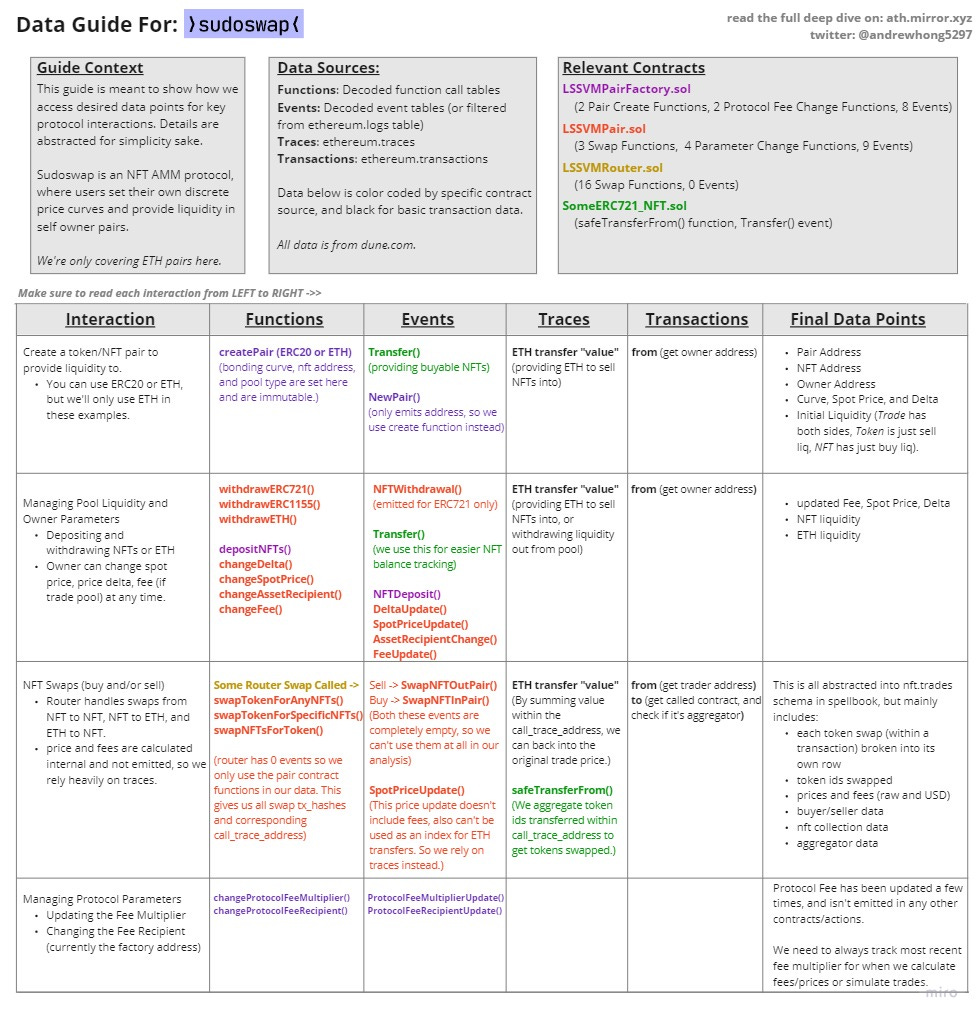
Some contextual callouts that don’t fit in the diagram:
Contract patterns:
While the basic contract pattern is simple (factory produces a pair as a proxy clone, only the pair creator has ownership of tokens in that pair), there are actually many different variations of the pair contract based on the type of ERC721 and ERC20/ETH token.
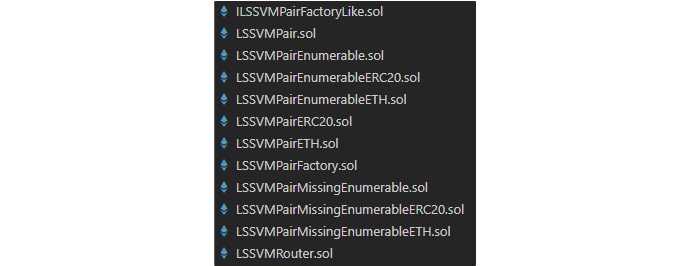
They all inherit from LSSVMPair.sol, and all the functions/swaps we care about are on that contract. To make our lives easier in Dune, we want all data to get decoded to the same contract table instead of seven different ones we then have to UNION over. I did this by compiling LSSVMPair.sol using hardhat, and pasting the ABI artifact in the contract decode request field under the name LSSVMPair_General.
Prices and parameters:
Spot price is set at the pair deployment, after each swap, and can also be set manually. The same SpotPriceUpdated() event is used for swaps and manual changes, but not emitted on deployment. This means we have to do an extra join when getting price histories, and also an extra join if we want to remove custom spot price changes from swaps data. It would be nice if there was a SpotPriceChanged() event for deploy and manual changes, so the data is cleaner. Same feedback for price delta.
Events, events, events:
My main gripe is that the router has 0 events for swaps, and the pair has empty events for swapping in and out. Including spotPriceOld, spotPriceNew, protocolFee, ownerFee, and tokenIds transferred in the swap events would have saved a lot of time and warehouse compute.
Thankfully Sudoswap has great docs and 0xmons was very responsive, so I was able to eventually piece together the data by manually going through internal traces for each transaction.
Internal traces are the function calls that happen within the main function call. In this case, the pair contract calls the NFT contract to transfer the NFT to the pair, then the pair contract makes an opcode call to transfer ETH from the contract to your wallet to complete the swap. Get price info and other read function calls also show up in internal txs as long as its a call across contracts (internal functions won’t show up in traces).
The best way to visualize this is using an explorer like Versatile blocksec, which visualizes transactions really well:
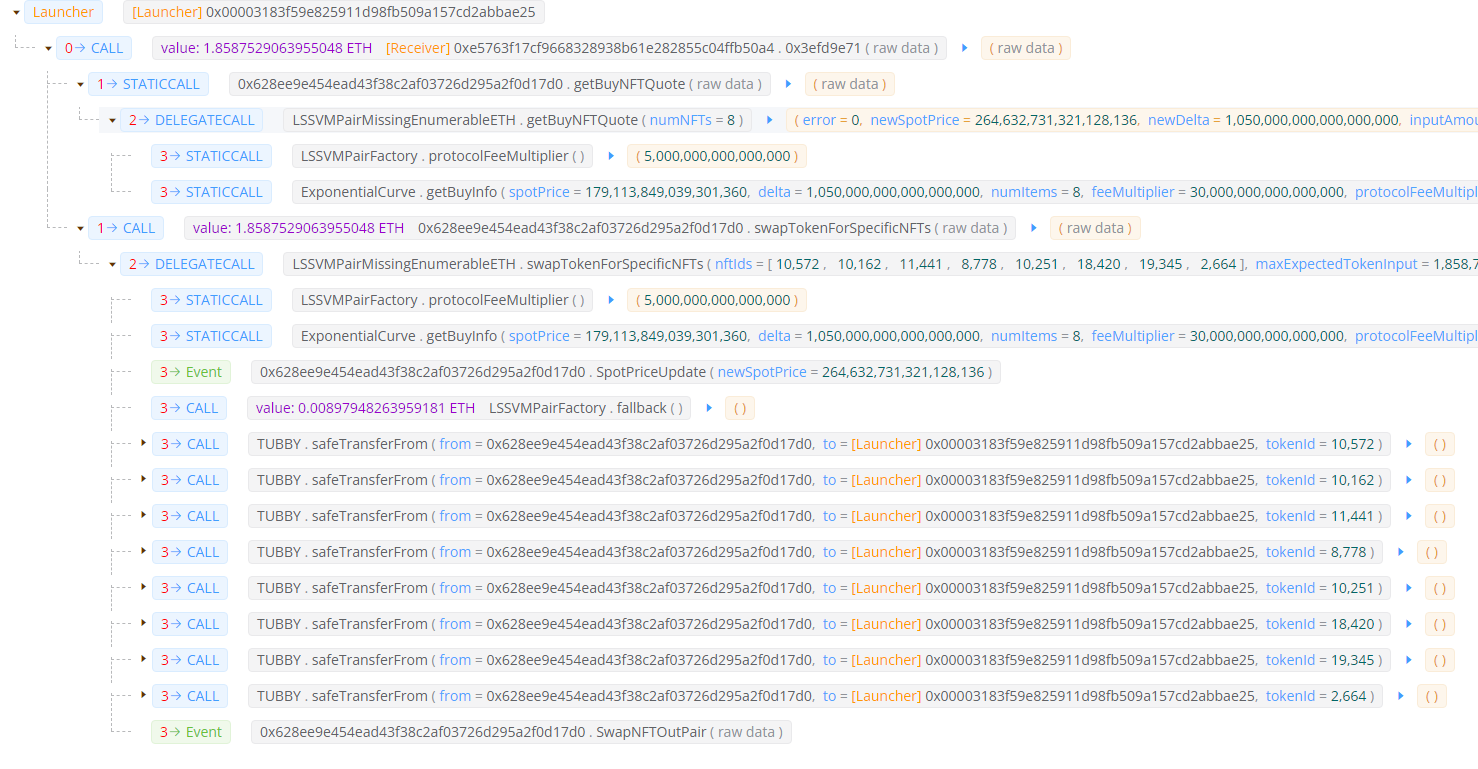
Dune v2 engine tables include the call_trace_address for all decoded functions, which means we can join with ethereum.traces and then filter for ETH calls (look at call value) and safeTransferFrom() call (0x42842e0e funcsig) within that subtrace stack. Then add on some simple math, and we can back into protocol fees and owner fees paid per swap.
You can find the full query below, which has some extra logic to fit into the nft.trades schema.

You can get started querying these tables yourself using any of the sudo_amm_ethereum tables or the abstraction sudoswap_ethereum.events , both on the v2 Dune engine!
Creating the Spellbook Abstraction
Dune’s v1 engine used an abstractions repo to create tables such as dex.trades and nft.trades by putting together enhanced tables out of decoded contract tables. Spellbook is for the v2 engine, this time built off of dbt (data build tool).
It’s a powerful way to semantically manage relationships between tables, easily generate documentation, and run tests. You also get to leverage Jinja to have more programmability around your SQL code (if, while, for loops, etc).
If you’re looking to contribute you can start with the Spellbook readme here, I’ll cover an example for Sudoswap trades below.
Getting your local environment set up:
First, you’ll need to install python and pipenv. I use anaconda to install and manage my python packages. Make sure you add the relevant scripts folders to your environmental PATH variable to be able to call commands globally. Once you’re able to call pip --version without errors, then you’re good to go!
fork and create a branch of abstractions on GitHub; we’ll PR back to main later.
Run
pip install pipenvand add it to your environmental PATH variable (you should be able to find the folder path by searching forpipenv.exe).Make sure you’re pointing to the spellbook folder path, and then run
pipenv install.Run
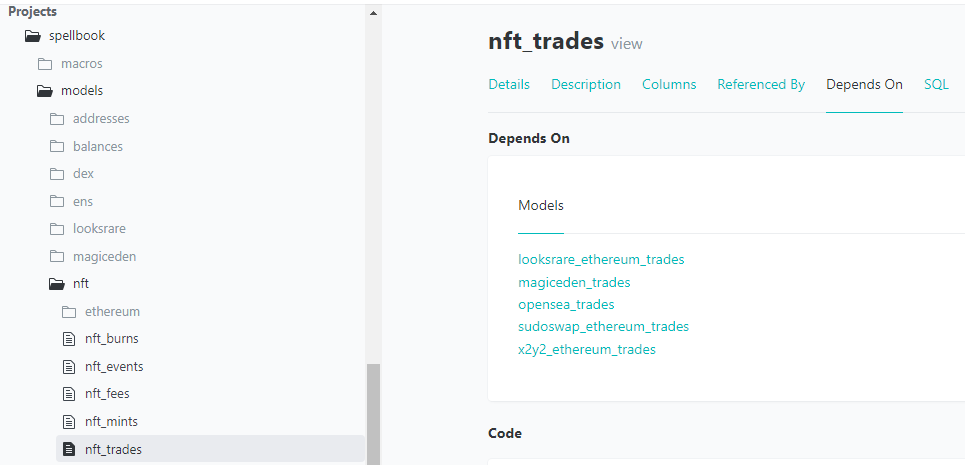
dbt init, you can putnfor all responses and put anything for credentials. Make sure you putwizardin for schemaNow you can run
dbt docs generateanddbt docs serveto look through the models (tables):
Anytime you want to test your queries in the dune engine, you can run dbt compile and look in the target folder for the compiled SQL.
Sudoswap PRs:
Here are the two PRs I made for Sudoswap. You can look at the “files changed” tab to see all the code I added. Most of what I changed can be found within the Sudoswap/ethereum folders within models and tests.
First one with all the main logic
Second one with some lines changed to fix prices and explode swaps so each token id gets its own row
For simple models, you just need a few steps:
define a
sources.ymlwith the decoded tables you want to use (base tables likeethereum.transactionsare already defined elsewhere so you don’t need to specify them again.create a
some_model.sqlfile with the filename as the table name you want to create. Don’t worry too much about the config for now; just use the following:
{{ config(
alias = 'some_model',
materialized = 'incremental',
file_format = 'delta',
incremental_strategy = 'merge',
unique_key = ['some_unique_key']
)
}}
These tables usually update incrementally as defined in config, unless you’re just creating a static table like
tokens_ethereum_erc20.sql. All you need to do is place the following filter wherever it makes the most sense (to transform all of the new rows). In my case we apply this on all swap functions since we only want to add the newest swaps to the table.
{% if is_incremental() %}
-- this filter will only be applied on an incremental run. We only want to update with new swaps.
AND call_block_time >= (select max(block_time) from {{ this }})
{% endif %}
Make sure to add your new model into a
schema.sqlfile with all your final columns defined. The more description and documentation you can add, the better!Add your folder models/schema into the
dbt_project.ymlfile.Lastly, you should make sure to have some tests. I recommend adding some not_null tests to key columns in your schema file, but you can also make more custom SQL tests.
After you compile your models and test them in the dune v2 engine interface, go create a PR and wait for reviews!
Simulating Liquidity Depth Across Pairs (i.e. Routing)
One of the more fun and complex queries I made for Sudoswap was simulating buying or selling X number of NFTs across all pairs to get total profits, costs, liquidity, and slippage.
You can observe the steepness of the price curve for any NFT collection that has pairs on Sudoswap, and see where there are inflection points once liquidity for pairs pricing at the same spot price, delta, and curve runs out (basically like moving between ticks on Uniswap v3, but not following a xy=k constant product curve).
")
The main simulation query can be found here. The full walkthrough and creation of the buy side of this query can be found on YouTube here. Sell side simulation was a little more complicated since we have to calculate maximum NFTs that can be sold into a pair based on ETH liquidity, spot price, and delta. For exponential curves, we can calculate it directly with geometric finite series summation formulas. For linear curves, because the pair stops processing trades if spotPrice is going negative, we calculate for the nth term where spotPrice = 0 and then truncate by ETH balance. The key logic is in the pairs_max_sell CTE, if you have questions or suggestions on how to calculate it more exactly/efficiently please let me know!
You’ll notice that Total ETH Liquidity is greater than the total profits you can make by selling NFTs (left side of cumulative area chart) - this is because some pairs have a spot price higher than the ETH held in the pair, so it’s technically illiquid.
There’s also one protocol technical nuance in this query is how the buy price and sell price are calculated. Pair bonding curves work by incrementing/decrementing the spot price by some delta along the curve. So if it’s linear, you do newPrice = spotPrice + delta, and if it’s exponential then you do newPrice = spotPrice^delta instead.
While the sell price is the current spotPrice, the buy price is the current spotPrice + one delta. 0xmons explained the rationale behind this decision as
“if
spotPricewas both the price to buy and sell, lps could be arbed (e.g. buy at 1 eth, spot price goes up to 1.1 eth, then sell for 1.1 eth)” - 0xmons
You’ll see this logic used in the parts of the query where I calculate simulated_prices, slippage nominal and slippage_percentage.
That’s a wrap!
I’m excited for the protocol to release ERC1155 and ERC20 support, as well as more bonding curves (Gradual Dutch Auctions have been teased 👀). I’ll do a part 2 of this guide once those come out.
I hope you enjoyed this data guide - please collect, subscribe, and share if you did! I’m open to any feedback on how to make these guides better so don’t hesitate to DM me on Twitter.