

UX Research to Improve NFT Auction Experience, using Mempool Data
Mempool data tells us a lot about what *kind* of user behaviors we are dealing with

User experience (UX) describes how people feel when they interact with a system or service and encompasses several factors including usability, design, marketing, accessibility, performance, comfort, and utility. Don Norman once said,
“Everything has a personality; everything sends an emotional signal. Even where this was not the intention of the designer, the people who view the website infer personalities and experience emotions. Bad websites have horrible personalities and instill horrid emotional states in their users, usually unwittingly. We need to design things — products, websites, services — to convey whatever personality and emotions are desired.”
Ethereum's personality is someone who is extremely inscrutable and easily misunderstood. To make matters worse, most users don't even think about it as interacting with Ethereum when they're using your interface or a wallet. If you're ever in the live chat of an Artblock's auction, you'll notice as soon as an auction ends there are at least a dozen people complaining that it is Metamask's fault that they didn't get a mint. I think in the last year the UX of many dapps on Ethereum has improved greatly in both product interaction and explainability of transactions. For the most part, dapps don't just leave you with a loading spinner after you sign the transaction anymore.
Even with the design of dapps is generally improving, I'm not sure how deep UX research has gone yet. When I see data analytics or research on various protocols, users are mostly treated as homogenous. This is somewhat shifting with some of the analysis I've seen of Uniswap V3 liquidity providers and Rabbithole Questers, but even those are still heavily focused on just confirmed transactions on-chain. From my own experience, most of the emotion evoked and behavioral quirks happen when I'm submitting, waiting, speeding up, or canceling my transaction. For some applications, the user might leave and go do something else after submitting a transaction. But for a product like Artblock's auctions, they're going to stay around until the confirmation has happened, likely checking anything they can for updates and with compounding anxiety.
I think we can do a much better job of understanding user behaviors and frictions by starting to leverage the mempool more. The mempool is where unconfirmed transactions are temporarily stored by a node. This means if you submit, speed up, or cancel your transaction then those actions will show up in the mempool first. It's important to note that the data from the mempool is not stored in the node, so you can't query historical data the same way you could on confirmed transactions. For example, you could observe that someone submitted a few transactions, sped up the transactions quite a few times at the same gas price, and saw confirmations 20 blocks later. I believe studying their behavior throughout the transaction lifecycle is a pretty good proxy for user experience and likely emotions they were feeling throughout the whole process. If we understand how different groups of users behave in this cycle, we can figure out how to supplement their decision-making or ease their anxiety. To my knowledge, pretty much only the Ethereum Foundation, All Core Devs, and some wallet teams leverage the mempool data for UX reasons.
UX Research Thesis: By looking at a user's behavior through auctions over time and also their wallet history, we can start to give behavioral identities to different groups of users. From here, we can identify the main issues to try and alleviate. We'll do this by taking a month of Artblocks Auctions data using Blocknative, and layering in the history of these addresses using Dune queries.
This article will be more technical than some of my previous ones since I believe the work can and should be generalized fairly easily. I want to emphasize that my background is not in UX research, I'm purely experimenting with what I think crypto-native UX research could look like.
Data Sourcing and Preprocessing All Auction Data
If you have no interest in the technical bits, skip to the next section on Feature Engineering
Blocknative and Mempool Data Streaming
Using Blocknative's Mempool explorer, you can filter for transactions submitted to specific contracts or from specific wallets. In my case, I wanted to listen to the whitelisted minter contracts for Artblock's NFT contract. You can find the stream that I used here, and save it down if you want to use the exact same setup.
You can find the whitelisted minter addresses with the following query in their subgraph:
{
contracts(first: 2) {
id
mintWhitelisted
}
}
There were three steps to get to a subscription filter for all purchases:
Add the new address with the "create new subscription" button
Add the ABIs by clicking the "ABI" button next to the address. In my case I just needed the "purchase" function.
{
"inputs": [
{
"internalType": "uint256",
"name": "_projectId",
"type": "uint256"
}
],
"name": "purchase",
"outputs": [
{
"internalType": "uint256",
"name": "_tokenId",
"type": "uint256"
}
],
"stateMutability": "payable",
"type": "function"
}
Add filters for the
methodNamematchespurchase(make sure you don't do a global filter)
In the end, your setup should look like this:

To store this data down, I created a ngrok/express endpoint to store in an SQLite database, run locally. I've created a GitHub template with steps to replicate this setup. Probably the most important point to remember here is that you need to include the POST endpoint as part of the ngrok URL when adding it as a webhook in the Blocknative account page.
Key Preprocessing Functions
Multiple Transaction Hashes
When you speed up or cancel a transaction, the original transaction hash is replaced with the new transaction. This means if you want to track a users' transaction through its full lifecycle, you need to reconcile the new transaction hashes with the original one. Assuming you speed up a transaction five times, you'll have six hashes total (the original hash + five new hashes). I reconciled this by getting a dictionary mapping of tx_hash to the new replaceHash, and then replaced recursively.
replaceHashKeys = dict(zip(auctions["replaceHash"],auctions["tx_hash"])) #assign tx_hash based on replacements, just to keep consistency.
replaceHashKeys.pop("none") #remove none key
def recursive_tx_search(key):
if key in replaceHashKeys:
return recursive_tx_search(replaceHashKeys[key])
else:
return key
auctions["tx_hash"] = auctions["tx_hash"].apply(lambda x: recursive_tx_search(x))
Blocknumber Issues
Dropped transactions have a blocknumber of 0, so to deal with this I sorted my dataframe by timestamp in ascending order, and then did a backward fill so the 0 would be replaced by the correct blocknumber it was dropped in. This is important fix for feature engineering.
auctions = auctions.sort_values(by="timestamp",ascending=True)
auctions["blocknumber"] = auctions["blocknumber"].replace(to_replace=0, method='bfill') #deal with dropped txs that show as blocknumber 0
Dealing with Mints Outside of Main Auction Period
For most projects, the artist will mint a few pieces before the auction opens up to the public. Some projects don't sell out right away, so you will get mints still occurring a few days after the auction has opened. My analysis is focused on the key auction period, mostly the first 30 minutes. To get rid of the two mint cases above, I removed outliers based on blocknumber.
to_remove_indicies = []
for project in list(set(auctions["projectId"])):
auction_spec = auctions[auctions["projectId"]==project]
all_times = pd.Series(list(set(auction_spec.blocknumber)))
to_remove_blocktimes = all_times[(np.abs(stats.zscore(all_times)) > 2.5)]
if len(to_remove_blocktimes)==0:
break
to_remove_indicies.extend(auction_spec.index[auction_spec['blocknumber'].isin(to_remove_blocktimes)].tolist())
auctions.drop(index=to_remove_indicies, inplace=True)
Adding on Dutch Auction Prices
For all projects in the dataset besides project 118, a Dutch auction price format was used. I took the mint price data using a dune query, and then merged it onto the dataset. I had to use a forward and backward fill for the blocks that had mempool actions but no confirmations during the auction.
auction_prices = pd.read_csv(r'artblock_auctions_analytics/datasets/dune_auction_prices.csv', index_col=0)
auctions = pd.merge(auctions,auction_prices, how="left", left_on=["projectId","blocknumber"],right_on=["projectId","blocknumber"])
auctions.sort_values(by=["projectId","blocknumber"], ascending=True, inplace=True)
auctions["price_eth"].fillna(method="ffill", inplace=True)
auctions["price_eth"].fillna(method="bfill", inplace=True)
Feature Engineering For Each Auction
If you have no interest in the technical bits, just read the parts in bold and skip the rest.
In data science, a feature is a variable that is calculated from the larger dataset to be used as an input in some sort of model or algorithm. All features are calculated in the preprocess_auction function and are calculated per auction rather than combining all the auctions into a feature set.
The first set of features are the totals for transaction states, and was a simple pivot_table function:
number_submitted: total number of transactions submittedcancel: count of transactions that ended in canceledfailed: count of transactions that ended in faileddropped: count of transactions that ended in droppedconfirmed: count of transactions that ended in confirmed
I mentioned earlier some data was not captured for auctions due to various issues, these transactions were dropped from the dataset.
The next set of features included their gas behavior. The key concept here was capturing how far away their transaction gas was from the average confirmed gas per block (shifted by 1 block). Then we can create features for the average, median, and standard deviation of gas price distance over the whole auction. There are a bunch of transposes and index resets to get the blocknumber columns in the right order, but the important function is fill_pending_values_gas which forward fills the gas price between actions captured. This means that if I put in a transaction at blocknumber 1000 with a gas of 0.05 ETH and my next action wasn't until blocknumber 1005 where I sped up to 0.1 ETH gas, then this function will fill in the blocks between 1000-1005 with 0.05 ETH.
def fill_pending_values_gas(x):
first = x.first_valid_index()
last = x.last_valid_index()
x.loc[first:last] = x.loc[first:last].fillna(method="ffill")
return x
The third set of features were calculating the total number and frequency of actions taken in the auction. Here we start with a pivot of total actions (speed ups) per block, with some special calculations for getting the first instance of pending for each transaction:
get_first_pending = df[df["status"]=="pending"] #first submitted
get_first_pending = get_first_pending.drop_duplicates(subset=["tx_hash","status"], keep="first")
auctions_time_data = pd.concat([get_first_pending,df[df["status"]=="speedup"]], axis=0)
time_action = auctions_time_data.pivot_table(index=["sender","tx_hash"], columns="blocknumber",values="status",aggfunc="count") \
.reindex(set(df["blocknumber"]), axis=1, fill_value=np.nan)
From here we get to average_action_delay in three steps:
we take the number of actions per block (yes some people sped up transactions multiple times in the same block)
we drop the blocks with no actions, and then take the difference between the blocknumbers that remain. We add a 0 for each additional action taken per block.
Taking the mean across the differences and added zeroes gives us the
average_action_delay
def get_actions_diff(row):
row = row.dropna().reset_index()
actions_diff_nominal =list(row["blocknumber"].diff(1).fillna(0))
#take the blocks with muliple actions and subtract one, then sum up.
zeros_to_add = sum([ actions - 1 if actions > 1 else 0 for actions in row[row.columns[1]]])
actions_diff_nominal.extend(list(np.zeros(int(zeros_to_add))))
actions_diff = np.mean(actions_diff_nominal)
if (actions_diff==0) and (zeros_to_add==0):
return 2000 #meaning they never took another action
else:
return actions_diff
total_actions is much simpler, as it is just the sum of actions across the pivot.
time_action["total_actions"] = time_action.iloc[:,:-1].sum(axis=1)
The last time-dependent feature is block_entry, which is an important one due to the introduction of Dutch auctions. Essentially this tracks what block the transaction was submitted on since the start.
get_first_pending["block_entry"] = get_first_pending["blocknumber"] - get_first_pending["blocknumber"].min()
entry_pivot = get_first_pending.pivot_table(index="sender",values="block_entry",aggfunc="min")
price_eth is added as a feature as well, which is tied to the block_entry point.
The last set of features were based on a Dune query, specifically the days since the first transaction, total gas used in transactions, and the total number of transactions. To get the address array in the right format I used the following line of code after reading in the SQL data:
all_users = list(set(auctions["sender"].apply(lambda x: x.replace('0x','\\x'))))
all_users_string = "('" + "'),('".join(all_users) + "')"
The dune query for this is fairly simple. I pasted the addresses string under VALUES, and made some CTEs to get the features I wanted. In the final SELECT I tried to add each address's ens as well. You can find the query here: https://dune.xyz/queries/96523
Lastly, we just merge in the per wallet data on days active, total gas used, and the total number of transactions.
auctions_all_df = pd.merge(auctions_all_df,wh,on="sender",how="left")
auctions_all_df.set_index(["sender","ens"],inplace=True)
With all this done, we're finally ready to run some fun unsupervised learning algorithms and try and validate our hypothesis on user groups.
Clustering and Visualizing User Groups
Before I started this project, I had expected to see the following user groups pop out of the data:
Set and Forget: There should be two groups here, those who set a transaction with really high gas and an average/low gas and then don't touch it for the rest of the auction.
Speed Up: There should be two groups here as well, those who are speeding up often and updating the transaction directly as a factor of gas prices and those who are speeding up often but with basically no change in gas price.
I was very interested in validating these groups, seeing how large each group was, and seeing if any users moved between groups over the course of many auctions. The easiest way to do this was to use unsupervised machine learning to identify clusters of user groups based on the variability across all features. Essentially this is like looking at the distribution of income in a state and then splitting it into sub-distributions for different income concentrations, geographic coordinates, and age. Note that this isn't binning, where the distribution is split into equal ranges - it is instead calculated based on the density of observations within the whole range. The approach we will take is called "unsupervised" because our dataset doesn't have any existing labels, rather than something like a regression where there is a value being predicted that can be verified as right or wrong.
The algorithm I decided to use is called k-means, where k stands for the number of clusters you are expecting to identify. Each cluster has a "centroid", which is like the center of a circle. There are various methods for figuring out how many clusters are optimal, and the two I used were elbow points and silhouette scores. Those are both fancy ways of asking,
"does each additional cluster help increase the density of the cluster (calculated as the average distance of points in a cluster from the centroid) and maintain adequate separation between clusters (no overlap between two clusters)?"
I found that 3 clusters were optimal in terms of most inertia improvement while keeping a high silhouette score (around 0.55).

With clusters chosen, we want to be able to visualize and verify their existence. There are over 15 variables, so we need to reduce the number of dimensions in order to plot it. Dimension reduction typically relies on either PCA or t-SNE algorithms, in our case I went with t-SNE. Don't worry too much about understanding this part, these algorithms essentially capture the variance across all features to give us X and Y components that maximize the spread of points from each other.
Let's look at project 118, LeWitt Generator Generator, from August 4th:
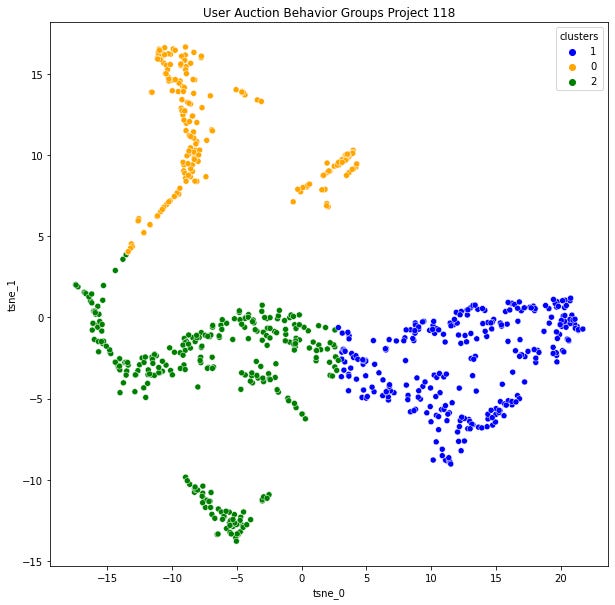

After taking a look at the sub-distributions for each variable and some data examples, I was able to categorize the clusters. The Orange cluster is the group that is speeding up the most while also submitting slightly lower gas transactions on average. Blue and Green clusters exhibit similar behavior to each other, but addresses in Blue typically have less history than addresses in the Green cluster.
Looking at the overall picture, it seems the original hypothesis on "speed-up" and "set high and set low" producing two groups each was wrong. Instead, we have a single "speed-up" group (Orange) and a single "set-and-forget" group (Blue and Green are behaviorally the same). I think the new (Blue) versus old wallets (Green) in the "set and forget" group probably carries a lot of overlap in actual users, where users just created new wallets to bid on more mints. Based on their impatience in average_action_delay and lower-than-average average_gas_behavior, the "speed-up" group reads to me as less experienced and more anxious than other users. What did surprise me is that the speed-up group makes up a smaller proportion (30%) of total bidders, as I had expected that group to make up 60-70% of bidders instead.
Now, where this user behavior study gets really interesting is when comparing project 118 (the set price of 0.75 ETH) to project 140 (Dutch auction with the price decreasing from 1.559 to .159 ETH).
Here's the clustering for project 140, Good Vibrations from August 21st:


We can see that now most of the clustering variability comes from block_entry, price_eth, and all of the gas_behavior features. This is a big departure from the main variables for project 118. In 118, the set price meant that people entered the auction in a fairly uniform distribution (quantity left didn't seem to matter), and the "speed-up" group submitted actions up fairly endlessly.
In project 140, we don't see the same difference in actions within average_action_delay or total_actions , instead, we see a new group (Orange) entering at a very late stage block and setting far below-average gas prices as seen in average_gas_behavior. If I was to try and map this to the clusters in 118, I believe the "speed-up" group has now become the "greedy" group (Orange) that is entering late and bidding a low gas. The Green cluster probably represents users with more experience than the Orange cluster, but who are still transitioning between Orange and Blue in terms of their behavior. The "set-and-forget" group maps pretty well to the "early-grab" group (Green and Blue) since they all exhibit pretty good patience and an adequate safety net on gas bids.
I call the Orange group "greedy" not just because of their behavior, but also because of their rate of failed transactions.
For project 118, fail rates are of the "speed-up" versus "set-and-forget" groups are within 10-15%.
 / number_submitted")
For project 140, the fail rate of the "greedy" cluster is around 69% versus the "early-grab" group at around 5-15%.

Overall, my read of this is that the group's bad habits and emotions were amplified - it feels to me like we made a tradeoff in anxiety → greed. This may have made the auction less stressful, but ultimately led to more users being upset (due to failed mints).
I'm sure there's a more granular analysis that can be done to segment the auctions further based on factory/curated/playground or by artists themselves too. This will only get more interesting and complex as the community continues to grow, and emotions play a larger factor in both a single auction and on if they return for future auctions.
This study of multiple auctions helped us validate our assumptions, understand the proportions of user groups, and see how users' good or bad behaviors shift over time (and other parameters). Now we need to plug it into the rest of the product cycle process.
Where We Go From Here:
The reason that I chose just Artblocks auctions for this and not a mix of platforms is because I wanted to look for a place where the variability in terms of interface and project type is mostly controlled. This should have given us fairly consistent users and behavior types.
This is just the start of a UX research cycle, so ideally we could continue in the following steps:
Use an unsupervised machine learning algorithm to identify the user groups (clusters) and see how many people are making "mistakes" when entering an auction. This is the step we covered today.
Create a new user interface, such as a histogram view on the bidding screen, or showing historical data on when most people usually enter/crowd the auction and at what prices. Anything to give both current and historical context to the user, especially those from the speed cluster.
With each auction, run the mempool/wallet data through the created algorithm to see if the user groups have shifted and if specific users have "learned" to participate in the auction differently (i.e. did they move between user groups). I think that the most value can be found in this step if done well. Using ENS or other identifiers to help supplement this grouping would be exponentially helpful too
Based on the results, continue to iterate on the user interface and design. You could also run more informed A/B testing since you could even figure out what screens to show by making an educated guess based on the users' last cluster (or use label propagation for new users).
The Dutch auction-style change is also an example of step #2, and we were able to see a clear shift in user behaviors. While typically this sort of research and testing is focused on increasing engagement or conversions, here we are optimizing for the user's ability to learn and improve instead. This may become even more robust if this was iterated in a multiplatform context, so that we can study how someone is learning at an ecosystem level (maybe even supplement with Rabbithole data and user profiles). Since my Artblocks user research is all based on publicly sourced data, it can be replicated and supplemented by any other auction/sale platform. Crypto could be the first industry that would have a synchronized and transparent set of user groups and UX research, to be applied in products and academia. Nansen wallet labeling is already a step towards this, but it's different when teams from different products build this up from various facets and approaches.
What I would eventually envision is using data to build on the following user personas (with subgroups/levels within them):
I want to buy a Fidenza, so I can either buy one through a private sale, bid on one in an auction myself, bid on one in a prtyDAO bid auction, or buy a fraction of one with fractional.art
I like Fidenzas in general, so I'll just buy the NFTX Fidenza index token or an NFT basket of Artblocks Curated on fractional.art
I'm a collector already, so I want to swap or bid on a Fidenza using a curated set of NFTs and ERC20s I already hold (using genie-xyz swap).
I like the rush of acquiring through initial mint versus secondary market, and heavily participate in auctions like Artblocks live mints.
I hope you found this project interesting and/or helpful, I had a ton of fun with it. Thanks to the folks at Blocknative for setting me up, and the community at Artblocks for answering my many auction questions. As always, feel free to reach out with any questions or ideas you may have!
You can find the GitHub repo with all the data and script here. The script may be a bit hard to read since I’m still refactoring and cleaning it up. The script and some of the analysis here may get updated as I analyze the last few auctions of August for new patterns.