

(8) Composability Series: The "Modular Stack" for Dummies
How the "modular stack" unlocks new design space for applications. Written for the non-technical reader.


I’m sure you’ve heard of a bunch of these technical terms: MEV, ePBS, SUAVE, Sequencers, Intents, Smart Accounts, User Operations, Bundlers, Relayers, MPC Wallets, Zero Knowledge Proofs, Restaking, Proto-danksharding (EIP-4844), Data Availability Sampling, Rollups, etc.
These are all part of the “✨ Modular Stack ✨”. If you’ve avoiding them because you think they’re overcomplicated or only pertinent to rollup security/scalability then hey - I get it. I was in the same boat until a couple months ago, when I started to understand the application design unlocks they provide.
I want to dumb the stack down into an easier-to-manage mental framework for two reasons:
For an easier time remembering the narrative connecting these technologies for those who don’t read every new article or thread - because the discourse is truly tiring to follow.
To take an application-focused view on all this new tech, rather than an infrastructure-focused view. 99% of the content I see on these topics is purely written for an infrastructure audience and targets those building the chains, not those building on the chains.
Designing a Transaction
Users and developers at the app layer primarily care about getting the most out of their transactions - customizability, speed, and data transferability.
I break these transactions down into three main stages:
Plan: What does the user want to do?
Ordering: What happens when we have multiple user actions, and the users and the apps have different goals (preferences)?
Execution: How do we track the results of actions (state) in a smart contract?
Until now, as a developer, you had to code all your application logic into the smart contract. You had to stick to 12-word seed phrase wallets, you had to force users to sign multiple transactions to go through your app, you had to stick to very simple math (or learn assembly), you had to work with only onchain data and no APIs, and you had to fit into a chain that tried to scale for every use case. Developers were stuck in the isolated and monolithic space of the Ethereum Virtual Machine (EVM).
The “Modular Stack” is a collection of technologies designed to change all that, so application developers can tailor their development environment to the desired user experience, while remaining permissionless, composable, and minimizing trust assumptions.
This diagram provides an overview of the various parts of this ecosystem that I will touch on:
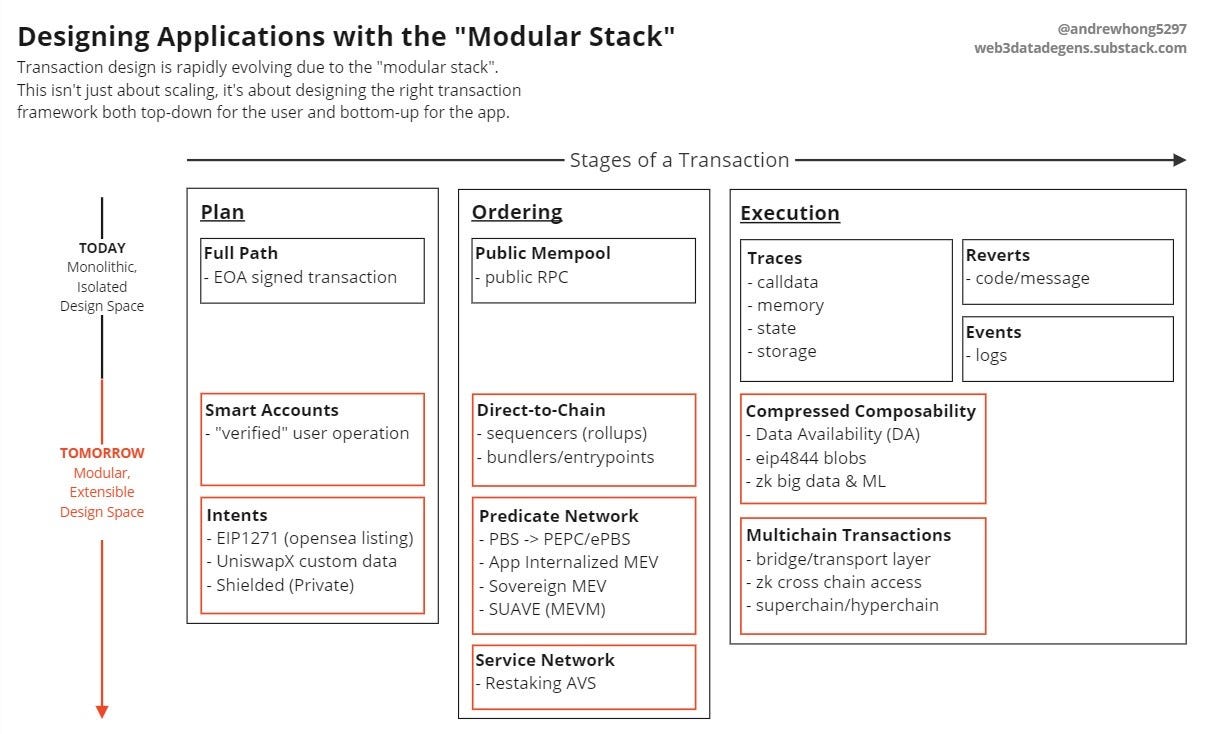
This framework revolves around the question:
“What is the design space of a transaction, really?”
I’ll spend this article defining the design space for a transaction, explaining what is being abstracted and added at each stage with each technology. I’m going to be as succinct and non-technical as I can and will provide links to more technical articles in case you want to read into them.
Transaction Plans: Smart Accounts and Intents
Historically, users have signed a “full path” transaction using a seed-phrase “wallet”, where the path contains the contract being called and the action(s) being taken. It goes into a public mempool (queue ordered by fees), and the full path is reflected onchain through traces, events, and reverts. All users and transactions are treated the same in this model.
Now, we’re seeing the abstraction of:
The “wallet” into a “smart account”
The “full path” into “operations and intents”
While “abstraction” means that we are simplifying the user journey and their mental overhead, for developers, this technology unbundles one wallet piece into many different pieces.
This unbundling is happening because when the wallet moves away from the seed-phrase model and into the smart contract, developers can design new experiences and flows, such as sponsored transactions for easier onboarding of users who don’t have any ETH and also new verification methods of transactions besides seed-phrase signing.
Smart Accounts and Verification Systems
This shift is enabled by ERC4337 “smart accounts”, which is a smart contract wallet with a multi-step submission process that separates verification, gas payment, and execution. I’ve written about their differences from other wallet types (EOA/MPC/SC). As of August 2023, we’ve already seen over one million operations from these smart accounts.
A transaction sent by a smart account is called a “user operation”. Operations are usually “full path” because you still sign exactly what you want to execute. You submit operations to a bundler (an API) who then sends batches of operations to an entrypoint (a smart contract that checks the verifications on each operation) which then calls the smart contract wallet (the “smart account”) and executes the operation.
Let’s start with the verification side. Typically, the only verification is the “signature” from the wallet. With smart accounts, you get something akin to how multi-signature safes work. The application developer building the smart account contract can decide what combinations of verifications will allow a submitted operation to be processed. There can be many different rules for verifications. This is not just about making web2 logins possible - that’s the wrong mental model.
A common current pattern is to tie that extra verification function to another seed-phrase to control the smart account. While that may sound circular, we can use an MPC wallet to generate this base seed-phrase and tie the signature to biometrics like your mobile Face ID - giving us much better UX and security. The hottest new fad friend.tech uses an MPC wallet setup, albeit without a smart account, because they don’t have a reason to have multiple verification methods or sponsor your transactions (yet).
One of the coolest smart account experiments I’ve seen with smart accounts is the recent Visa + Gnosis Pay (L2 rollup) integration:

How can the blockchain work seamlessly with existing external systems? They give you a Visa card that allows you to spend your balances on Gnosis Pay chain with any supported Visa merchant. While the implementation spec is not fully released yet, I imagine that the smart account has a multi-sig verification structure where I have to go through the card + Visa multi-signature method to spend my tokens at a VISA merchant:
The signature connected to your visa card chip
Visa’s (or SEPA’s or Mastercard’s) signature after going through the normal KYC/fraud checking process
I could still move funds to/from my smart account on Gnosis Pay whenever I want with just my EOA single signature (the “favorite wallet” mentioned in the diagram above). This assumes the Gnosis Pay bundler (the API that takes your operations and sends them onchain) allows you to submit arbitrary blockchain operations to the smart account without going through Visa’s API.
Remember the sponsored transactions part? This involves a paymaster who can pay for the gas of your transaction for you. Visa could choose to pay the gas only when you use your Visa card, but then not sponsor any other operation types.
We will likely see a world where a user will have many different accounts tied to different operations supported by different verification methods and sponsorships. Check out the safe {core} protocol for potential advanced implementations.
Now it’s actually realistic for a user to have many different smart accounts - it was never realistic for a user to have many different seed-phrase wallets. Infrastructure providers like Alchemy, Biconomy, and Stackup make it easy to plug and play. It makes sense for apps to build their own “smart account” wallets now with custom onboarding and verification methods. Before this, wallet innovation was mostly focused on the interface level, showing balances across defi tokens and previewing transaction execution intuitively. That was just a game of aggregating the most contract interfaces you could - and I’m sure that layer will still exist (and become more customizable) after all these smart accounts pop up.
Intents: Starting Simple
Okay, so what are intents? The formal definition of intents is still unclear, but it’s essentially:
“Giving approval for someone (or some group) to execute an action on your behalf given a set of your preferences, over a period of time”
The simplest example everyone refers to is the Opensea bid/listing, where you sign a message that gives approval to Opensea to transfer your NFT to someone else in exchange for some amount of tokens.
Some chains like Solana actually send even these bids and listings completely onchain through transactions. You could still consider those “intents” even if they are already onchain, since the user’s desire has not been fulfilled yet.
Where this gets interesting is when a whole middle network is spun up to coordinate and process these intents, before the execution is finalized onchain. The “transaction” that ends up onchain could be an ordering of many intents that most efficiently settles the state across accounts. Or a single intent might be settled in multiple transactions for a single intent, spanning across many blockchains.
Wtf does any of what I just said mean? Let’s get into middle networks next - or more formally known as predicate networks.
Transaction Ordering: The Predicate Network
Some networks sit after the account plan and before final execution on the blockchain, which is responsible for ordering and bundling operations/intents/full paths into blocks (or even into a single transaction). I will call these predicate networks, where predicate means both “before” and “preferences”. I know that transaction ordering seems really boring and abstract, but it’s important because applications are about to gain a lot more control here - so stick with me!
Thanks to Robert Miller for using “predicate” in your SUAVE presentation. Sorry for taking it slightly out of the intended context.
Defining the Predicate Networks
These predicate networks have three key parts:
Relayer: someone receiving transactions (or intents) submitted by users and then sending them onchain. Stuff like the rollup sequencers or ERC4337 Bundlers are the most naive “Relayers” who send transactions onchain in the order they receive them. You can build in a network between the two relayer steps (receiving → predicate network (solving/building) → proposing → blockchain).
Predicate: Some set of preferences that need to be satisfied to give priority to a set of transactions to get through onchain. These preferences already exist even in the public mempool, which is supposed to order them naively by the gas fee. You could even pay a lot to propose a block with a single transaction. MEV systems have evolved from this to make “maximal value extraction” opportunities from stuff like arbitrage more efficient and secure for the solvers.
Solver: Someone who is ordering transactions to optimize for some formula. The formula could be as simple as arbitraging token pairs across Uniswap and Sushiswap. They have to search for transactions (or intents) that are relevant to them, and then they send their ordering logic back to the relayer once they have figured out an order that satisfies the formula. They are the ones who place “bids” to the relayers based on how profitable their ordering is for them. This role can be split into many different agents, depending on the setup.
There are three types of predicate networks being built, from what I’ve seen:
Generalized Predicate Network: The current MEV network breaks down the relayer and solver into many different agents with Proposer-Builder Separation (PBS). Flashbots plays the role of a “relayer” accepting and sharing transactions (as full path, not as intents) and then the “solver” is split into a “searcher” and “builder” who look for arbitrage opportunities within the public mempool and the Flashbots relayed transactions. They then submit these ordered transactions back to Flashbots, who send them to validators to add to the next block in the blockchain. The base L1 ethereum blockchain does not know this is happening, it just has to execute the EVM code. This means that it will keep pumping out blocks regardless of how the predicate network decides to operate. If you’re curious about the evolution of the PBS MEV network, check out Mike’s great presentation on them. All transactions qualify for the generalized predicate network, anyone can be a solver, and applications have to suck it up and deal with the consequences of it. If none of that made sense, don’t worry about it - I’m not going to talk more about them.
Enshrined Predicate Network: It’s considered “enshrined” when the “generalized predicate network” is built into the blockchain. This one has not happened yet but has a ton of discussion with stuff like enshrined PBS (ePBS). It seems difficult to build an intent solver layer on top of the fee system into the EVM, but some people smarter than me are excited about it. This one interests me because when app developers create a rollup they can decide to change the rules of transaction ordering to be something like strictly first come first serve (FCFS). So the more flexibility programmed into the base layer, the more customization these app developers on rollups will have. This base layer rule changing has been referred to as “sovereign MEV”, and I think the best example is DyDx doing this on a Cosmos appchain.
Application-Specific Predicate Network: This is the most emergent network type, built with a complete focus on intents! It’s specifically taken off with decentralized exchanges (DEX), with protocols building swap intent networks like Cowswap and UniswapX. They take your token swap intents and ask solvers to find matches with external market makers and onchain DEXs with the specific predicate of pricing swaps at market rates efficiently. This combination of direct transfers and dex transfers across multiple users gets put into one “batch” transaction. There is deep research on auction systems for solvers here, focused mostly on DEX order flows. Right now, it’s a very centralized system, but I’m sure Cowswap/Uniswap will come out with clients and a full p2p gossip network at some point in the next year. This predicate network is not tied to a specific blockchain, so it can operate across chains. People have called this “App Internalized MEV” since the application captures any value extraction before anyone else can. I think this is kind of ABCI++ on Cosmos and kind of what SUAVE is trying to be.
Rollup sequencers and ERC4337 bundlers both directly send transactions onchain in batches in the order they receive them. There is a lot of discussion about building mempool infrastructure (which enables the first two predicate networks) into these, but that talk gets very technical very quickly. The third predicate network can be built on any chains/stacks.
I’ve butchered a lot of the nuance behind the networks and terms here to give an easier-to-digest explanation of everything. To get the full technical picture, read Jon’s work (1, 2). Ordering is usually referred to as one part of the more complex layer of “consensus”.
Designing an Application-Specific Predicate Network
What if we used “Application-Specific Predicate Networks” to do more than capture MEV - and instead allow applications and users to express their own sets of preferences? We can walk through the example flow of the diagram below for minting out an NFT collection:
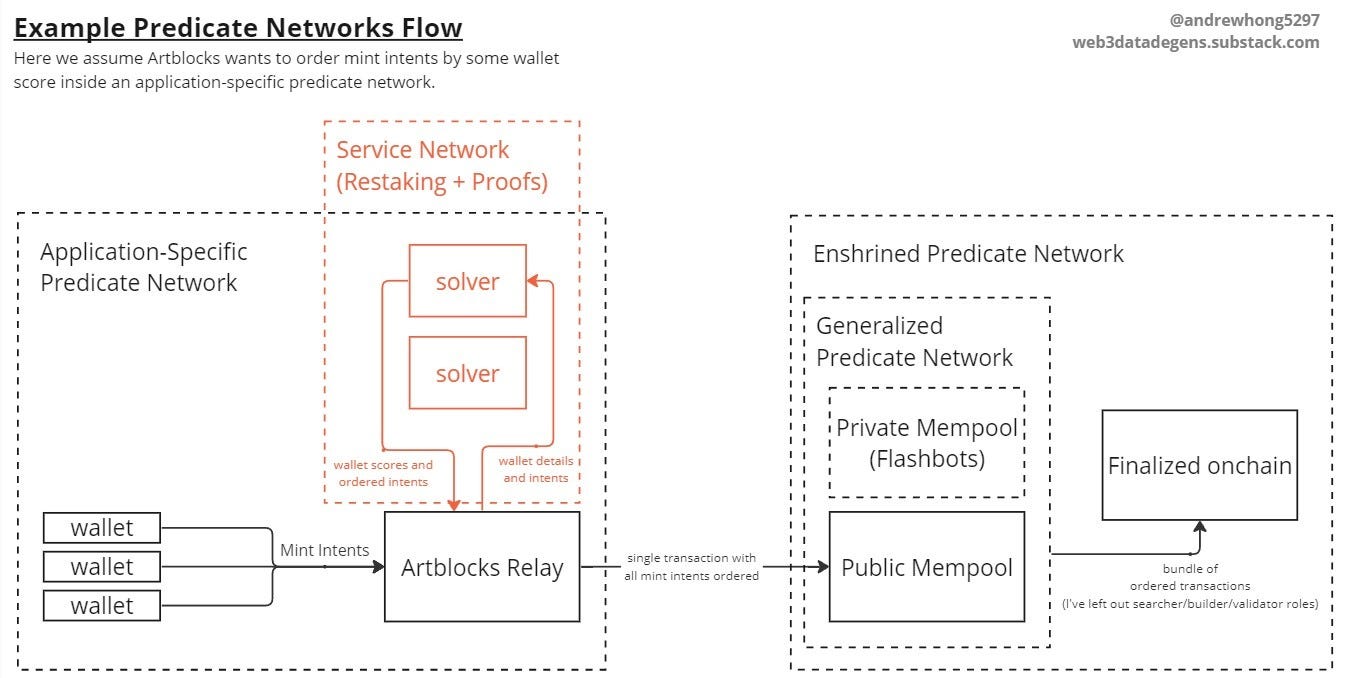
I’m using the Artblocks Curated Projects as an example. At the height of the bull market, these generative art projects were released every week or so with a supply of up to 1000 or so mints. Gas prices would spike, and many users were left really unhappy as projects minted out in minutes. I tracked the mempool for a month to show the clusters of users who struggled to mint anything and how they panicked. Artblocks used a dutch auction, where the price of the NFT decreases every 30 minutes or so along a set curve.
Let’s say Artblocks wanted to implement their preference to distribute supply to older wallets and collectors. They could implement a simple score based on some variables, such as wallet age and if you have flipped NFTs from curate projects before? The older the age and the less flipped NFTs, the higher the “priority” score you are given to mint. You can’t just reserve NFTs for the top 1000 scores, because then you have worse price discovery since these bidders know the competition is limited and will wait for the auction price to drop. Even if you limit supply, i.e. 100 mints among 1000 top scores, you would still want some ordering service so that gas price is not the competition angle (the default predicate) and that willingness to pay goes to the artist instead.
Users could submit their mint intents into an Artblocks Predicate Network where the solvers try and find an ordering by “priority score”. That ordering gets sent back to Artblocks, who will then commit all the intents in one transaction onchain, minting out the NFTs. The solvers are then paid out for their service, no bidding is involved in this case. I think many different kinds of scores would fit in well at the ordering layer, I’ve expanded on types of scores relevant to applications before.
In this example, it’s only the application expressing preferences. But you could allow users to express them as well, such as “I’ll pay 3 ETH for any mint I’m able to qualify for this month”. This way, the user gets to submit it just once and let the solver fulfill it anytime the user fits inside the “priority score” ordering. Does this all sound too far-fetched to build yourself? The good news is there are already companies like Brink working on making this easy to set up generically.
Note that the scores from solvers are never actually put onchain (all we see is the normal NFT mint function/event), but they will be stored in the services network for proofs. The NFT smart contract gets told only to accept mint intents from the Artblocks relayer.
Validating Services Used In External/Predicate Networks
In the example system, how do you guarantee that the solvers were honest about their scoring and ordering services? You need staking and slashing! The solvers can stake some token (put in a “deposit contract”) when they propose some ordering to the Artblocks relayer, and if they have been found to make a mistake in scoring, then part of their stake is “slashed” and sent to the entity that proved the mistake (or to the users affected). But does Artblocks want to create another token for this staking/slashing? Probably not - it is really hard to guarantee economic value for the token, unless they do some collateralization or stablecoin pegging (and we’ve seen dozens of protocols fail there alone). Instead, they can “restake” ETH that has already been staked with validators on Ethereum. The solvers can use protocols like Eigenlayer to “borrow” the restaked ETH, and participate in the Artblocks predicate network.
Eigenlayer calls the service being staked/slashed the “Actively Validated Service” (AVS) - and the service can really be anything, it’s not limited to use in a predicate network. This “restaking” validation pattern is already being used for ZK provers on bridges.
What? ZK provers? Bridges? Onto the last stage of the transaction: execution!
Transaction Execution: Compressed Composability
With more responsibility and logic moving to the “plan” and “ordering” stages, what is the purpose of the “execution” stage? I believe it exists to maximize composability. Composability means an application’s ability to carry state across accounts, contracts, and chains. A blockchain is required for composability because you can have a provable set of actions, states, and blocks that must continuously follow the same rules (unless you have a hard fork). What if we can compress more data and compute from outside into the blockchain? Then we get compressed composability.
Two technologies play together to enable this:
Data Availability (DA): Creating blockspace for more data onchain, which gets pruned (deleted) over time. It is no longer the blockchain’s job to store all the historical data, it only needs to validate the blocks going forward. The technology enabling this is “Data Availability Sampling (DAS)”.
Zero Knowledge Proofs (ZKP): Either proving some condition without revealing the underlying information, or proving that some information came from a specific set of computations. Cryptography has a long and complex history, you can read more about the ZK here.
Enabling Complex Compute for Applications
You’ve probably heard of ZK mostly in the context of ZK-rollups. That’s NOT what I care about here. I’m interested in what ZK unlocks for enabling more compute on more data onchain. Yi gives a great talk about “ZK Coprocessing” that I highly recommend, but the key slide is below:

If you’ve followed me from the start, you’ll know that many of these coprocessing examples speak to the heart of why I got into crypto. Here are a few interesting example use cases:
Access Basic Storage/State History: Prove someone was active within a given time period by checking historical nonces (a transaction counter), using the Axiom SDK
Worldcoin Identify Proofs: Prove you are a human without revealing who you are (transparently explained here).
Retroactive Public Goods Funding (RetroPGF), driven By Proof of Contract Usage: Build usage-value functions based on onchain data to retroactively reward contract developers from rollup sequencer revenue. Working with big data and ZK is still possible, Lagrange has taken proofs to the next level for this use case. This specific case is called Contract-Secured Revenue (CSR).
Fit Large Models Onchain: You can even fit LLM proofs onchain, to prove your output came from a prompt to a GPT model.
The great part about ZK proofs is that they are transport layer agnostic - so you don’t need a complex oracle system to get the data onchain. Anyone can post and verify the proof!
The applications here are limited by the proof size we can store onchain, and how quickly we can compute (or update) the proofs. Ethereum is adding proto-danksharding (EIP4844) as a first step to DA which allows an additional ~2MB of data to transactions in block (bringing the size maximum to 3MB). This extra 2MB gets pruned after a few weeks - and we assume someone out there has saved it for posterity. Right now, the use case for it is for storing proofs from rollups (which only need to stick around for a week or two until the rollup has hard finality) - but I’m sure we will see much use from ZK ML applications (to prove a model or function was used). We probably will see other neat things appear here, too - Bitcoin actually did something similar many years ago with segwit/taproot to bring their block size from 1MB to 4MB, and that led to Bitcoin NFTs (Ordinal Inscriptions).
You might say, “Andrew wtf are we going to do with an extra 2mb”, well that is fair, but there are solutions like Celestia that take data availability (among other things) to the extreme for much larger block sizes and plug in to rollups like Optimism. This enables stuff like onchain gaming, where data throughput needs to be pretty high. You can start building with this specific stack using Caldera. ZK Proof aggregation will also be key in making sure we can lower the costs of verifying proofs onchain.
Enabling Seamless Multichain Transactions
The other design space ZK proofs unlock is seamless multichain transactions. One transaction can kick off a bunch of subsequent transactions across chains, by passing along the ZK proof through bridges. A bridge is some infrastructure you put in the middle of two chains to send messages (also called a transport layer). You aren’t limited to just sending tokens, you can send some message like a governance proposal vote result to call a function on another chain. This architecture can be made more seamless by storing all proofs in one place using a light client to work between different types of chains or a “superchain”/“hyperchain” to work between the same type of chain. With these, you wouldn’t need to keep track of proofs on dozens of chains - you could check “does the user own X tokens on any chain” based on some aggregated balance proof. This multichain composability sometimes gets referred to as “settlement” layers.
Remember the ZK prover network I mentioned earlier? Now you have enough context to read about it, and you should know why its important to have a service network that can keep up with producing all these proofs. Chains can share many different types of service networks to become more operationally scalable.
User operations and intents will evolve further to be privacy-preserving at some point using ZK proofs too. This exists in Cosmos using Anoma’s “intent-centric architecture” through shielded transactions. And the age-old lesson is if it’s on Cosmos, it’s only a matter of a year or so before it ends up in Ethereum land.
Concluding Thoughts
Hopefully, you can now see how the technologies in the “modular stack” add as much value to the application layer as they do to the security and scalability of blockchains themselves. Each time you read about one, you should ask the question:
“what does this unlock for the design space of the transaction?”
I know many of these technologies sound unwieldy to build with - but I am pretty confident that the teams working on them are trying hard to make them accessible within the next six months. I’m a fairly average developer, and I can understand and get started with many of them right now.
And if you’re building this technical infrastructure and trying to go to market - go talk more about how your product actually helps application developers. You might have raised from VCs off the infrastructure stack and MEV narrative, but that story won’t get you actual developer adoption.
Thanks for reading all this. My DMs are always open if you have any questions or want to chat more. If you found it helpful, go like and share the tweet!
Thanks to Elena, Vishesh, and Kofi for your thoughts and review of this article ❤️
And thanks to Celestia for hosting Modular Summit and aggregating all these great presentations and speakers, all of whom are great writers too. If you have time, go watch all 20+ hours of talks (Day 1, Day 2), and then rewatch them. It’s truly excellent content that gets you excited about the future of crypto. Uma also has a great talk about all this you should be sure to watch - she gets slightly more technical, but not too technical.