

OpenRank: Building Graph Datasets for Contextual Crypto App Feeds
You've heard of pagerank, the algo that powers Google search. OpenRank supports a similar algo that will power the next wave of crypto applications - I'll explain and show you how to build with it.

Disclaimer: I am an investor and advisor to the OpenRank team.
Join our research mission the month of July to build the best graph datasets to power feeds for governance, nft mints, and social discovery.
Crypto frontends today mostly contain simple leaderboards - top tokens by volume, liquidity, mints, points, votes, etc. If we want to move into consumer crypto experiences that beat the behemoths of web2 today, we’ll need more than leaderboards in our app feeds.
OpenRank is one of the building blocks that will help get us there, and is already used by Metamask Snaps, Degen tips, and Supercast. OpenRank is a compute layer where many reputation graph algorithms can be run. The first of which is the eigentrust algorithm.
In this article, I’m going to introduce you to the OpenRank eigentrust algorithm and cover:
The importance of community built graphs, and why you’ll need them
Key concepts of the algorithm and how it works
Creating your own graph, referencing one I made myself in a python notebook
Let’s get into it!
I’ll be running a Bytexplorers mission within the next month where we’ll compete to make the best graphs for feeds on top apps in crypto - be sure to subscribe to be notified of when that kicks off!
Why build recommendation graphs with the community instead of only your own ML team?
When building algorithms and feeds in crypto, you’ll quickly face a few data problems:
Transactions contain many inter-layered actions
The relationships between addresses can be infinitely complex, built up over many transactions.
An address itself contains partial identities, each of which are relevant in different contexts.
All three of the above are ever-evolving at an exponential rate, let’s call those growing elements our “context”.
Your small ML team isn’t going to be able to keep up with this never-ending context.
You aren’t going to want to task your backend or data engineering team with this either, they have a product to build. The days of an application owning the user and user data structures is over. You don’t get a simple link, user id, like/reply/share, and post id anymore. You can have claims, splits, drops, swaps, stakes, delegated, voted, mints… there’s a new “action” that drops almost every day. And a new chain, new type of wallet, new type of identity… good luck with all that!
I believe we’ll see a graph data science community evolve in crypto in the next year, built around the OpenRank protocol and product.
I’ve been part of the wizard community at Dune for years now, and have seen the power that the community has over a small team. And I’ve seen almost every small team in crypto go from “yeah we can do this ourselves with a node and RDS database” to “we need to tap into community built data tools like the Graph and Dune”. To me, creating the combinations of queries and graphs tuned for specific kinds of feeds and communities is a similar problem. We’ll need to start collecting and testing graphs that can power feeds on every app from Farcaster clients to block explorers.
The idea of “one feed” is skeuomorphic and will be left behind. The user is the curator.
In crypto, users not only want to take their social graphs with them across apps, but the contexts hidden within them too. If I’m actively following the /degen community on farcaster, I want to see the actions of that community as the base of recommendations if I’m on Zora, Roam.xyz, or OnceUpon too. And I want to be able to toggle that feed to the context of another community I’m part of, say the artblocks collectors. The future will be one where users discover and pick their own feeds, out of contexts that are naturally occurring and created - not boxed within some group or channel feature on a single platform.
How does OpenRank Eigentrust work?
The eigentrust algorithm is similar to pagerank in that it ranks nodes in a graph network. The difference is that it focuses on capturing complex peer-to-peer relationships, as a distribution of trust. It was first built for assigning trust scores in a file sharing network. In crypto, you could imagine using this to proxy high-quality governance delegates or identify trustworthy smart contracts.
Below is the eigentrust formula you’ll soon become familiar with:

There are two key inputs above: pretrust nodes and localtrust graphs. "P" is your pretrust and "S" is your localtrust.
localtrust: this is your measurement of interactions between two nodes, as node “i” signals some value to node “j”. This could be a token transfer, attestation, vote reply/like, etc.
pretrust: this is your "seed" selection of nodes who you think should be more trusted in the network.
“c”: this constant (between 0 to 1) is a weighting of the trust value between the overall localtrust graph and the pretrust seed. Interaction graphs typically have power law distributions so a higher pretrust weight helps normalize the distribution of final ranked values.
If the math doesn’t make sense, think of a social graph like Twitter. Influence (followers, likes, replies) is typically concentrated on just a few individuals, leading to a power law dynamic. By setting a diverse set of influential individuals and selecting a constant “c” of 0.5 or higher, you’re essentially saying that the people those trusted individuals interact with shall inherit half the value of that influence. This is what equalizes and distributes the trust score across the network more evenly.
Inputs and outputs are all normalized, so it doesn’t matter the scale of the values you use for localtrust/pretrust. Outputs are also always between 0 and 1 from the eigentrust model.
How is this related to choosing any context and creating any feed?
Let’s say you wanted to create an NFT mint recommendation feed. You could use a localtrust of NFT transfers/sales, and create a pretrust of the top 100 wallets by USD value of transfers/sales. This would be a global feed, and one that likely closely mimics a generic leaderboard. Our goal here is personalization, so it’s important we actually select a more contextual set of pretrust nodes. So instead, you could create a list of 100 wallets ranked by number of artblocks curated projects minted. This will now affect the output graph in a way that artblocks community wallets (and those wallets within 2-3 degrees of the community) get the highest values of “trust” in the network. Now, your feed will be more personalized to the artblocks community. You could also plug in just your own wallet(s) into the pretrust, so that you get an output of what your closest friend wallets (and their friends) are minting onchain.
From this example, it should hopefully be clear that having a focus on the kind of feed you want to build will determine what input graphs you want to create. I know this may still be too abstract, so I’ll walk through a concrete code example in the next section. Remember, OpenRank handles the compute and storage of these eigentrust graphs, and recommends feeds you can use outputs in. All you have to do is decide on the pretrust and localtrust inputs.
How do you build a eigentrust graph with OpenRank?
The end goal
In this example, I want to provide a feed of recommended contracts based on the wallets of casters in the /base channel on Farcaster (it’s an app like Twitter). The output of eigentrust is just a list of ids and values, in my graph each id is tied to a farcaster user id (fid).
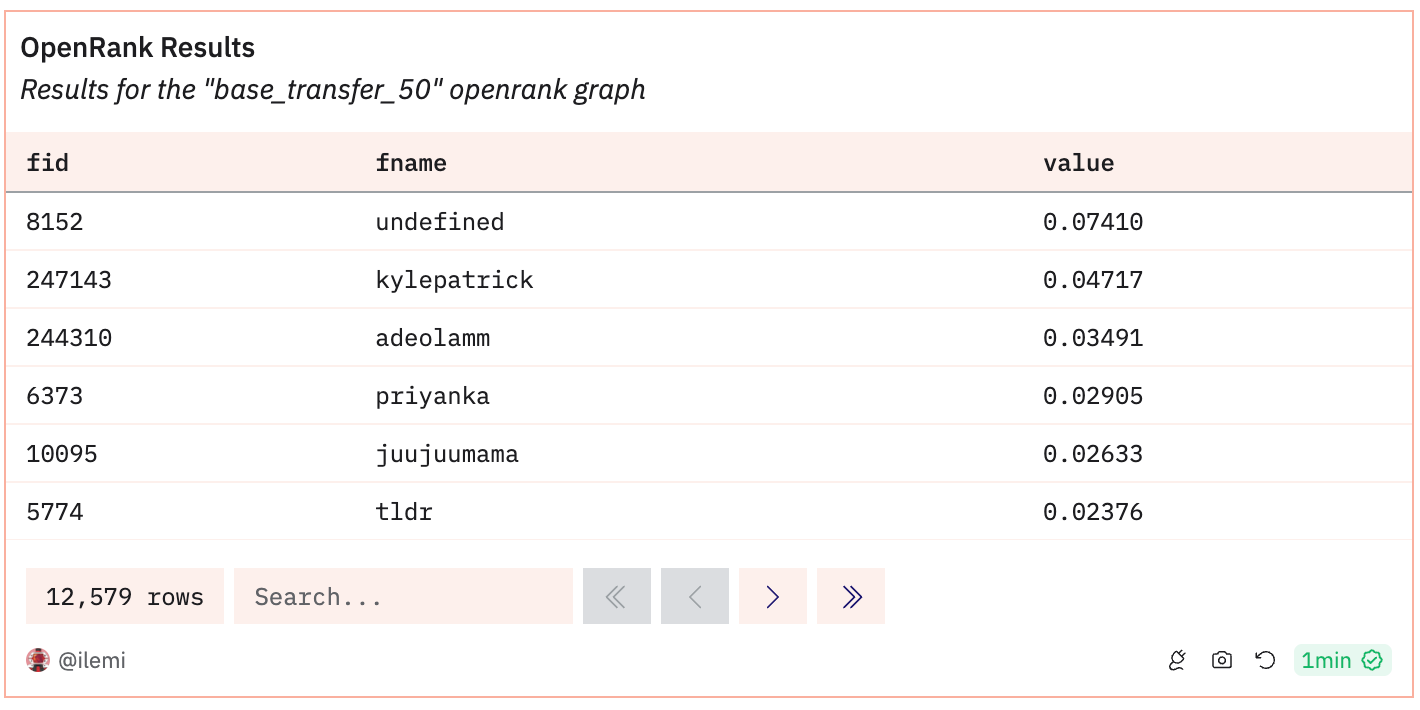
Remember that usually there is a power law dynamic in graph networks, so if I just took the top casters in the /base channel by number of casts or followers or engagement and used that to weight onchain actions, then it will be heavily dependent on just the top 10-20 casters. Using eigentrust, I’m able to more evenly disperse that trust across 12,000 casters instead which will give me a much more diverse weighting of onchain interactions.
After creating that eigentrust output, I weight their top contract interactions over the last week give us this recommendation feed:

You can check out this dashboard to see other feeds created from that graph, such as NFT minting, DEX token trading, and Farcaster channel activity.
Into the code of the model
Now that you’ve seen the end goal, let’s talk about how I created the ranked graph.
All code for this example can be found in this hex.tech notebook, and the jupyter notebook if you prefer to run locally.
To start our journey, I created two queries for our pretrust and localtrust respectively:
The first query is for our “pretrust nodes”. This query outputs the top casters in the /base channel based on engagement received (likes, recasts, replies), I take the (likes + 3*recasts + 10*replies) as my formula. We’ll be taking the top 100 ids from this query to use as our trusted nodes.

The second query is for tracking onchain interactions between nodes, using the linked addresses of casters in the /base channel. Because the feed is going to be recommending onchain actions, I want to make sure to choose an interaction graph heavily based off onchain interaction volume. Taking the USD value transferred between nodes is a good general proxy - I tracked stablecoin and ETH transfers on optimism, base, and ethereum mainnet.
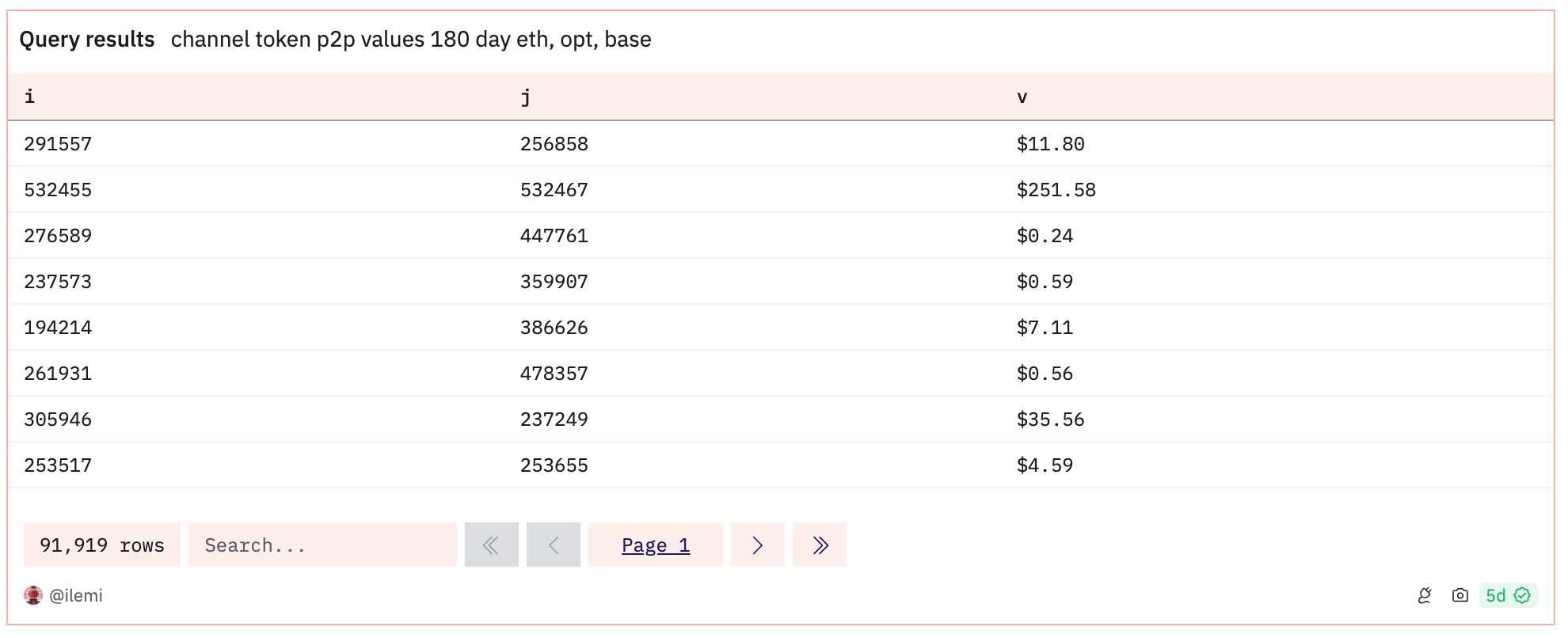
Analyzing our input graphs, and testing our output eigentrust graphs
Now that we have our pretrust nodes and localtrust graph, let’s check some summary statistics. There are 65,755 users in the /base channel who have transferred tokens to someone else in that channel, and from our pretrust nodes we are able to traverse 19% of the graph (i.e. connected nodes). This percentage may be much lower or higher depending on how sybiled the localtrust data of the graph is. Token transfers can be high signal, but can also be wash traded so it’s not surprising that much of the graph is disconnected.

After we have checked the input data is sensible in size and connection, we can run and save our eigentrust graph. I’ve saved mine to the id “base_transfer_50” - you can see below it only takes 10 lines to train the graph. Think of openrank sdk as the scikit-learn of crypto graph models.

Remember the constant “c” from the formula earlier? Let’s do a grid search with different c values (I call it alpha) and different pretrust seed sizes and see which gives us the most log-normal trust scores and highest coverage ratios:

There are many tradeoffs here, and no optimal value to aim for. High normalization and coverage is a nice behavior if you want a strong diversity of recommendations, but for something high stakes like governance voting you may actually want a higher concentration of trust. Use your own intuition here.
From here, we can plug in our values into the feed query from the dashboard linked at the start on Dune to get a contracts interaction feed from trusted users in the /base channel. This subjective feed output helps us better connect the generic metrics from earlier to our intuition on the expected quality of recommendation outputs.

And we’re done! You could use this Dune API to power any of your apps immediately.
Learn to build your own OpenRank eigentrust graphs
Are you excited and ready to build on your own? You can fork my notebook and try it yourself, all the links you need are here:
Join our research mission the month of July to build the best graph datasets to power feeds for governance, nft mints, and social discovery.
would it still work to do a openrank for channels using the same method?